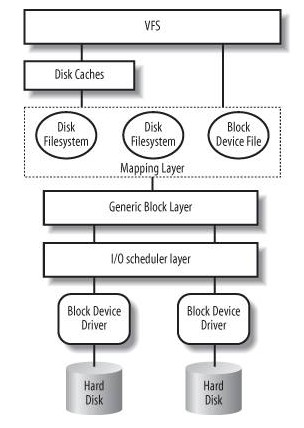
Linux文件系统分为多层,从上到下分别为用户层、VFS层、文件系统层、缓存层、块设备层、磁盘驱动层、磁盘物理层
- 用户层:最上面用户层就是我们日常使用的各种程序,需要的接口主要是文件的创建、删除、打开、关闭、写、读等。VFS层:我们知道Linux分为用户态和内核态,用户态请求硬件资源需要调用System Call通过内核态去实现。用户的这些文件相关操作都有对应的System Call函数接口,接口调用 VFS对应的函数。缓存层:文件系统底下有缓存,Page Cache,加速性能。对磁盘LBA的读写数据缓存到这里。文件系统层:不同的文件系统实现了VFS的这些函数,通过指针注册到VFS里面。所以,用户的操作通过VFS转到各种文件系统。文件系统把文件读写命令转化为对磁盘LBA的操作,起了一个翻译和磁盘管理的作用。通用块层和IO调度层:块设备接口Block Device是用来访问磁盘LBA的层级,读写命令组合之后插入到命令队列,磁盘的驱动从队列读命令执行。Linux设计了电梯算法等对很多LBA的读写进行优化排序,尽量把连续地址放在一起。磁盘驱动层:磁盘的驱动程序把对LBA的读写命令转化为各自的协议,比如变成ATA命令,SCSI命令,或者是自己硬件可以识别的自定义命令,发送给磁盘控制器。Host Based SSD甚至在块设备层和磁盘驱动层实现了FTL,变成对Flash芯片的操作。磁盘物理层:读写物理数据到磁盘介质。
 VFS
VFSLinux为了支持不同的底层文件系统,提供了一个中间层VFS,它为上层应用屏蔽了底层分拣系统的实现。
VFS中主要有四大对象,分别是:
- 超级块对象:代表一个具体的已安装的文件系统(从磁盘读取)索引节点对象:代表一个具体的文件(从磁盘读取)目录项对象:它代表具体的目录项,路径的组成部分文件对象:代表进程打开的文件
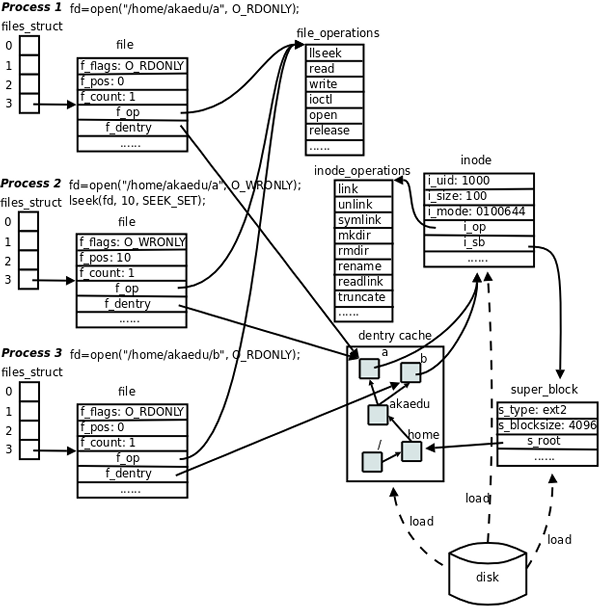
超级块对象
通常对应存放在磁盘特定扇区的系统超级块或文件控制块。对于非基于磁盘的文件系统,会现场创建超级块。保存文件系统的类型、大小、状态等等。
超级块提供的操作:创建,删除,修改inode;卸载,加载文件系统
索引节点对象
保存的其实是实际的数据的一些信息,这些信息称为“元数据”(也就是对文件属性的描述)。我们必须从读取磁盘中的inode到内存中,这样才算使用了磁盘文件inode。inode号是唯一的,文件和inode节点也是意义对应。当创建一个文件的时候,就给文件分配了一个inode。
索引节点提供操作:创建,删除,移动文件
查找文件(通过目录inode和待查文件dentry(提供文件名), 返回dentry(包含inode))
硬连接和软连接
- 硬连接:共享inode节点,只是增加inode计数。缺点是不能跨文件系统软连接:有自己的inode,只是使用路径名作为指针。可以跨文件系统
目录项
目录项是文件的逻辑属性,并不对应磁盘上的描述,为了加快查找速度而设计。
目录项状态:
- 已使用:d_inode指向相应的inode节点,并且d_count>0。表明正在被vfs指向有用的数据,不能丢弃。未使用:d_inode指向相应的inode节点,并且d_count=0。表明正在被vfs指向无用的数据,必要的时候可以回收。负状态:d_inode指向不存在的索引节点,d_inode=NULL。但是为了快速索引路径仍然可以保留,有需要可以回收。
目录项缓存(denry_cache)
- “被使用的”目录项链表:通过索引节点中i_dentry连接,因为一个索引节点可能有多个名字(硬连接),就有多个目录项“最近被使用”目录项:含有未被使用和负状态的目录项对象,从头插入,必要的时候从尾回收散列表和散列函数快速将给定路径解析为目录项对象
目录项和inode是绑定的,所以再缓存目录项的同时,也把inode缓存了。
目录项提供的操作:创建,删除目录项对象;通过路径名查找dentry
文件对象
文件对象代表一个已打开的文件,包含了访问模式,偏移量等信息。文件对象通过f_denty指向目录项对象,目录项对象指向inode节点,inode节点记录文件是否是脏的。
文件对象提供的操作:提供read,write,刷盘等操作
其他对象
- file_system_type:描述文件系统类型vfsmount:描述一个安装文件系统,主要是理清文件系统和其他安装点之间的关系(限制权限之类?)
进程相关数据结构
- file_struct:文件描述符表,文件对象指针数组fs_struct:文件系统和进程相关信息(工作路径,根目录路径,正在执行的文件)mmt_namespact:文件系统命名空间,大家都一样
页高速缓存是内核实现的磁盘缓存,它的作用是为了减少磁盘IO操作。缓存的存在有两个原因:匹配速度的不一致;局部性原理
读缓存和写缓存简介
下面先介绍物理页,块,和扇区。扇区是磁盘的单位,是磁盘操作的最小粒度;物理页和块是操作系统的概念,块是操作系统操作磁盘的最小单元。
物理页 >= 块 >= 扇区
读缓存
页缓存是由一个个物理页面组成的,它的大小可以动态调整。我们读取数据的时候首先先检查页缓存中数据是否存在,如果存在直接读取,如果不存在就从磁盘中读取,然后将数据放到页缓存中。
写缓存
一般而言,写缓存有三种实现方式:
- 不缓存:直接写到磁盘,并且标记页缓存中的数据过期写透缓存:写缓存同时写磁盘,保持了良好的一致性“回写”:只写到缓存中,标记页面为脏,过段时间刷新。脏页标记的是磁盘中的数据过期。
缓存回收
缓存空间有限,缓存回收策略至关重要。
- LRU:最近最少使用双链策略
Linux实现的是修改过策略LRU,称为双链策略。有两个链表,分别为热链表,冷链表。热链表上的页面不会被换出,冷链表上的页面可以被换出。页面首先加入冷链表中,如果再次被访问就加入热链表,当热链表过长,需要将溢出的页面重新加入冷链表。
Linux高速缓存
page_cache和buffer_cache
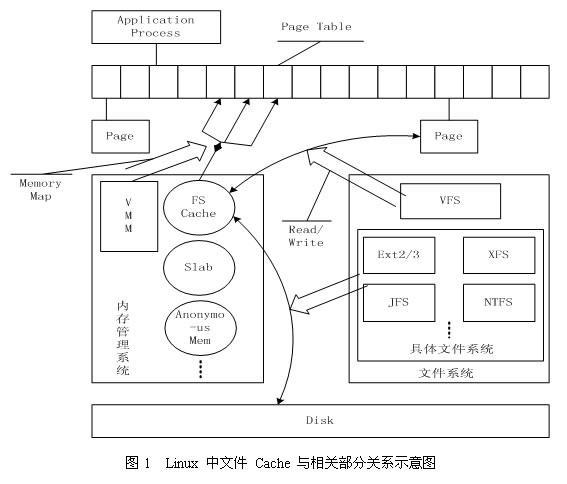
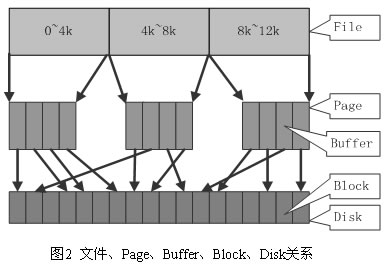
文件 Cache 分为两层,一是 Page Cache,另一个 Buffer Cache,每一个 Page Cache 包含若干 Buffer Cache。内存管理系统负责维护每项 Page Cache 的分配和回收,同时在使用 memory map 方式访问时负责建立映射;VFS 负责 Page Cache 与用户空间的数据交换。而具体文件系统则一般只与 Buffer Cache 交互,读缓存以Page Cache为单位(主要是为了加速,其实只需要读需要的buffer cache就行),每次读取若干个Page Cache,回写磁盘以Buffer Cache为单位,每次回写若干个Buffer Cache。
address_space对象
一个物理页可能包含了多个不连续的物理磁盘块,一个物理页大小是4K,一个块大小通常是512B。因为文件可能存在于多个块中,所以也不要求页面映射的块连续。也正是因为磁盘块不连续,所以通过块号来做页高速缓存的索引是不可行的。
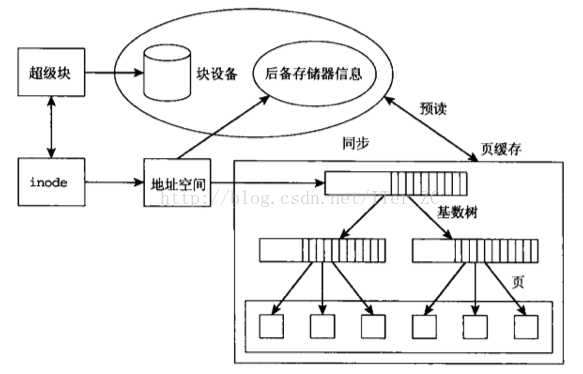
Linux引入了一个新对象管理缓存项和页IO操作,称为address_space对象,是vm_area_struct的物理地址对等体。address_space这个概念来作为文件系统和页缓存的中间适配器,屏蔽了底层设备的细节。一个文件inode对应一个地址空间address_space。而一个address_space对应一个页缓存基数树。这几个组件的关系如下
文件读写流程
读文件
- 用户发起read操作操作系统查找页缓存若未命中,则产生缺页异常,然后创建页缓存,并从磁盘读取相应页填充页缓存(只需要读取相应的块?)若命中,则直接从页缓存返回要读取的内容用户read调用完成
写文件
- 用户发起write操作操作系统查找页缓存若未命中,则产生缺页异常,然后创建页缓存,将用户传入的内容写入页缓存分配page,具体原理是将page内的每个buffer与物理磁盘块建立映射。我们只填充需要用到的buffer_head,将buffer_head设置为脏若命中,则直接将用户传入的内容写入页缓存用户write调用完成页被修改后成为脏页,操作系统有两种机制将脏页写回磁盘用户手动调用fsync()由pdflush进程定时将脏页写回磁盘
问题:为什么普通读写文件需要两次,而mmap只需要一次。
- read/writemmap第一次读到page_cache读到page_cache第二次读到用户空间mmap映射
直接IO
一开始,提到过直接IO。
当我们以O_DIRECT标志调用open函数打开文件时,后续针对该文件的read、write操作都将以直接I/O(direct I/O)的方式完成;对于裸设备,I/O方式也为直接I/O。
直接I/O跳过了文件系统这一层,但块层仍发挥作用,其将内存页与磁盘扇区对应上,这时不再是建立cache到DMA映射,而是进程的buffer映射到DMA。进行直接I/O时要求读写一个扇区(512bytes)的整数倍,否则对于非整数倍的部分,将以带cache的方式进行读写。
使用直接I/O,写磁盘少了用户态到内核态的拷贝过程,这提升了写磁盘的效率,也是直接I/O的作用所在。而对于读操作,第一次直接I/O将比带cache的方式快,但因带cache方式后续再读时将从cache中读,因而后续的读将比直接I/O快。有些数据库使用直接I/O,同时实现了自己的cache方式。
通用块层和IO调度器在Linux Block IO层,有三种关键的数据结构。Linux page、buffer_head、bio。
DMA操作
对磁盘的读写是按段为单位的
简单DMA操作
数据段在内存中必须是连续的
分散/聚集DMA
可以段在内存中分散,写到连续的扇区
page
buffer_head
buffer_head顾名思义,表示缓冲区头部。这个缓冲区缓冲的是磁盘等块设备数据,而buffer_head则是描述缓冲区的元数据。同时,它是VFS读写数据的基本单元,是VFS眼中的磁盘。
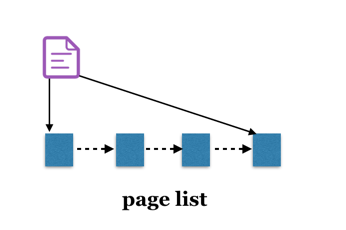
page与buffer_head数据结构之间关系如下图所示:假设page大小为4KB,而文件系统块大小为1KB。
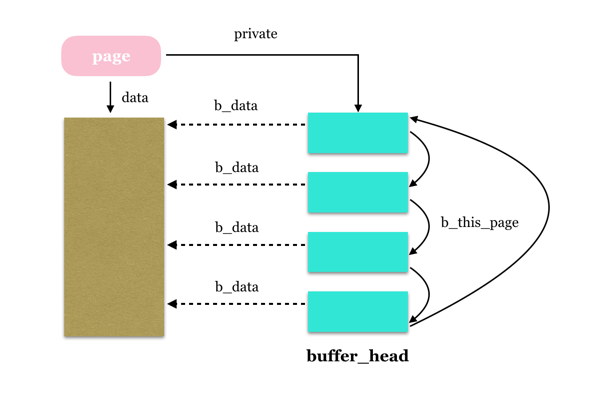
- page通过private字段索引该page的第一个buffer_head,而所有的buffer_head通过b_this_page形成一个单循环链表;buffer_head中的b_data指向缓存文件的块数据;buffer_head内还通过b_page指向其所属的page(图中未画出)
bio
buffer_head是kernel中非常重要的数据结构,它曾经是kernel中I/O的基本单位(现在已经是bio结构)。但是这样会存在一些问题。
- buffer_head只能代表一个块,而bio可以代表非连续的一个或多个页bio结构可以充分利用分散/聚集 IO方式bio结构可以代表直接IO,也能处理文件系统的请求
因此,我们向磁盘读取页面,需要先将buffer_head封装成bio,再向通用块层发送请求。
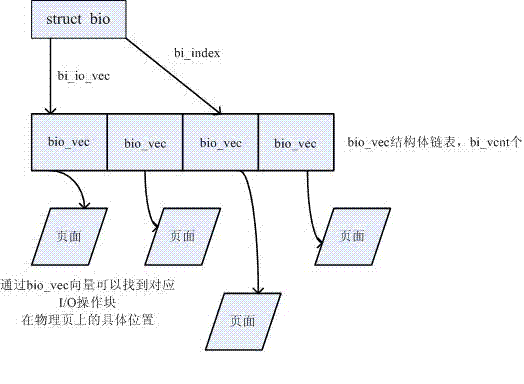
struct bio {
sector_t bi_sector; //512
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev;
unsigned long bi_flags; /* status,command,etc */
unsigned long bi_rw;
unsigned short bi_vcnt; /* how many bio_vec's */
unsigned short bi_idx;
unsigned int bi_phys_segments;
......
// bio完成时的回调函数
bio_end_io_t *bi_end_io;
void *bi_private;
bio_destructor_t *bi_destructor;
struct bio_vec bi_inline_vecs[0];
};
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};IO调度
块IO层接收了bio请求,通过IO调度算法,将bio加入IO请求队列。
这里的关键在于将bio合并至某个request内,所谓的合并指的是该bio所请求的io是否与当前已有request在物理磁盘块上连续,如果是,无需分配新的request,直接将该请求添加至已有request,这样一次便可传输更多数据,提升IO效率,这其实也是整个IO系统的核心所在。
函数elv_merge()负责合并操作,具体逻辑是:
- 可以后向合并:该bio可以合并至某个request的尾部;可以前向合并:该bio可以合并至某个request的头部;无法合并:该bio无法与任何request进行合并。
Linux中的IO调度算法:Noop算法,Deadline算法,Anticipatory算法,CFQ算法
Noop算法
Noop调度算法是内核中最简单的IO调度算法。Noop调度算法也叫作电梯调度算法,它将IO请求放入到一个FIFO队列中,然后逐个执行这些IO请求,当然对于一些在磁盘上连续的IO请求,Noop算法会适当做一些合并(根本不排序)。这个调度算法特别适合那些不希望调度器重新组织IO请求顺序的应用。
这种调度算法在以下场景中优势比较明显:
- 在IO调度器下方有更加智能的IO调度设备。上层的应用程序比IO调度器更懂底层设备。对于一些非旋转磁头式的存储设备,使用Noop的效果更好。
Deadline算法
Deadline算法的核心在于保证每个IO请求在一定的时间内一定要被服务到,以此来避免某个请求饥饿。
Deadline算法中引入了四个队列,这四个队列可以分为两类,每一类都由读和写两类队列组成,一类队列用来对请求按起始扇区序号进行排序,通过红黑树来组织,称为sort_list;另一类对请求按它们的生成时间进行排序,由链表来组织,称为fifo_list。每当确定了一个传输方向(读或写),那么将会从相应的sort_list中将一批连续请求dispatch到requst_queue的请求队列里,具体的数目由fifo_batch来确定。
对于读请求的期限时长默认为为500ms,写请求的期限时长默认为5s。
文件常用操作:cat file :显示一个文件
cd :切换目录 cd ./ cd .. cd ~
cp filea fileb :把a->b
mv filea b :把a->b
file fname :识别文本类型(文本,二进制)
find pathname option(-name file):查找文件/目录
head file :显示文件开始位置
tail :显示文件尾部
less file :从开始或结尾浏览文件
more file :从头到尾浏览文件
ls -l -a:
mkdir :
pwd :显示当前目录
passwd :创建密码
rm file :删除文件
rmdir file :删除空目录
whereis :显示文件目录
which :如果文件位于path中,则显示文件位置实例
根据文件或者正则表达式进行匹配
列出当前目录及子目录下所有文件和文件夹
find ./homefind /home -name "*.txt"同上,但忽略大小写
find /home -iname "*.txt"当前目录及子目录下查找所有以.txt和.pdf结尾的文件
find . \( -name "*.txt" -o -name "*.pdf" \) 或 find . -name "*.txt" -o -name "*.pdf"
匹配文件路径或者文件
find /usr/ -path "*local*"基于正则表达式匹配文件路径
find . -regex ".*\(\.txt\|\.pdf\)$"同上,但忽略大小写
find . -iregex ".*\(\.txt\|\.pdf\)$"否定参数
找出/home下不是以.txt结尾的文件
find /home ! -name "*.txt"根据文件类型进行搜索
find . -type 类型参数类型参数列表:
- f 普通文件l 符号连接d 目录c 字符设备b 块设备s 套接字p Fifo
基于目录深度搜索
向下最大深度限制为3
find . -maxdepth 3 -type f搜索出深度距离当前目录至少2个子目录的所有文件
find . -mindepth 2 -type f根据文件时间戳进行搜索
find . -type f 时间戳UNIX/Linux文件系统每个文件都有三种时间戳:
- 访问时间(-atime/天,-amin/分钟):用户最近一次访问时间。修改时间(-mtime/天,-mmin/分钟):文件最后一次修改时间。变化时间(-ctime/天,-cmin/分钟):文件数据元(例如权限等)最后一次修改时间。
搜索最近七天内被访问过的所有文件
find . -type f -atime -7搜索恰好在七天前被访问过的所有文件
find . -type f -atime 7搜索超过七天内被访问过的所有文件
find . -type f -atime +7搜索访问时间超过10分钟的所有文件
find . -type f -amin +10找出比file.log修改时间更长的所有文件
find . -type f -newer file.log根据文件大小进行匹配
find . -type f -size 文件大小单元文件大小单元:
- b —— 块(512字节)c —— 字节w —— 字(2字节)k —— 千字节M —— 兆字节G —— 吉字节
搜索大于10KB的文件
find . -type f -size +10k搜索小于10KB的文件
find . -type f -size -10k搜索等于10KB的文件
find . -type f -size 10k删除匹配文件
删除当前目录下所有.txt文件
find . -type f -name "*.txt" -delete根据文件权限/所有权进行匹配
当前目录下搜索出权限为777的文件
find . -type f -perm 777找出当前目录下权限不是644的php文件
find . -type f -name "*.php" ! -perm 644找出当前目录用户tom拥有的所有文件
find . -type f -user tom找出当前目录用户组sunk拥有的所有文件
find . -type f -group sunk-exec找出当前目录下所有root的文件,并把所有权更改为用户tom
find .-type f -user root -exec chown tom {} \;上例中,{} 用于与-exec选项结合使用来匹配所有文件,然后会被替换为相应的文件名。
找出自己家目录下所有的.txt文件并删除
find $HOME/. -name "*.txt" -ok rm {} \;上例中,-ok和-exec行为一样,不过它会给出提示,是否执行相应的操作。
查找当前目录下所有.txt文件并把他们拼接起来写入到all.txt文件中
find . -type f -name "*.txt" -exec cat {} \;> all.txt将30天前的.log文件移动到old目录中
find . -type f -mtime +30 -name "*.log" -exec cp {} old \;找出当前目录下所有.txt文件并以“File:文件名”的形式打印出来
find . -type f -name "*.txt" -exec printf "File: %s\n" {} \;因为单行命令中-exec参数中无法使用多个命令,以下方法可以实现在-exec之后接受多条命令
-exec ./text.sh {} \;搜索但跳出指定的目录
查找当前目录或者子目录下所有.txt文件,但是跳过子目录sk
find . -path "./sk" -prune -o -name "*.txt" -printfind其他技巧收集
要列出所有长度为零的文件
find . -emptyls -l(这个参数是字母L的小写,不是数字1) 用来查看详细的文件资料
在某个目录下键入ls -l可能会显示如下信息:
文件属性(占10个字符空间) 文件数 拥有者 所属的group 文件大小 建档日期 文件名
(read,write exe权限)
drwx------ 2 Guest users 1024 Nov 21 21:05 Mail
-rw-rw-r--一共有10位数
其中: 最前面那个 – 代表的是类型中间那三个 rw- 代表的是所有者(user)然后那三个 rw- 代表的是组群(group)最后那三个 r– 代表的是其他人(other)
修改权限:chmod
例:rwx rw- r--
r=读取属性 //值=4w=写入属性 //值=2x=执行属性 //值=1
chmod u+x,g+w f01 //为文件f01设置自己可以执行,组员可以写入的权限 chmod u=rwx,g=rw,o=r f01 chmod 764 f01 chmod a+x f01 //对文件f01的u,g,o都设置可执行属性
文件的属主和属组属性设置
chown user:market f01 //把文件f01给uesr,添加到market组
ll -d f1 查看目录f1的属性-rw——- (600) 只有所有者才有读和写的权限-rw-r–r– (644) 只有所有者才有读和写的权限,组群和其他人只有读的权限
-rwx—— (700) 只有所有者才有读,写,执行的权限
-rwxr-xr-x (755) 只有所有者才有读,写,执行的权限,组群和其他人只有读和执行的权限
-rwx–x–x (711) 只有所有者才有读,写,执行的权限,组群和其他人只有执行的权限
-rw-rw-rw- (666) 每个人都有读写的权限
-rwxrwxrwx (777) 每个人都有读写和执行的权限
文件系统信息管理:
df -h
df -k
查看磁盘的使用情况
mout :查看文件系统
umout :删除文件系统