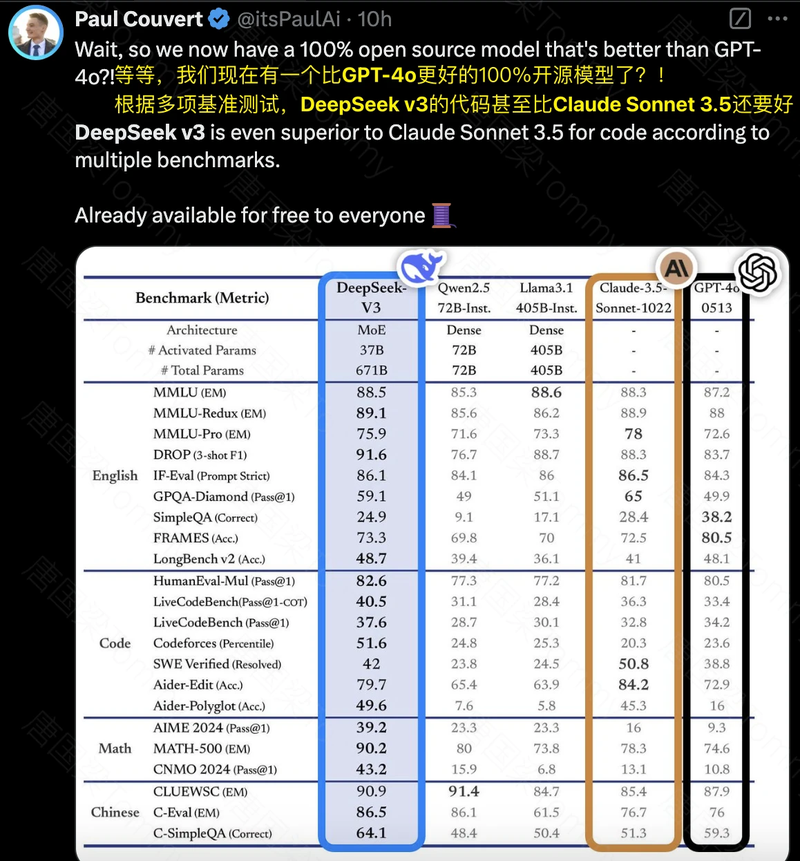
DeepSeek-AI 最新发布的 DeepSeek-V3,是一款采用 混合专家 (MoE) 架构 的大型语言模型,其参数总量高达 6710 亿,每次推理仅激活 370 亿参数。DeepSeek-V3 的开源不仅让这项前沿技术触手可及,也为模型创新和应用提供了新的机遇。该模型一经发布,便受到技术社区的高度关注,多位技术大佬在 Twitter (X) 上表达了对 DeepSeek-V3 的认可。有评论指出,DeepSeek-V3 的发布标志着开源 MoE 模型的新高峰,也有评论赞扬其在代码和数学能力上表现出色,370 亿激活参数的设计是其高效性的关键。
DeepSeek V3 的整体训练成本约为 557 万美元,这一数字相较于其他大型闭源模型(如 GPT-4o)的数亿美元成本而言,显得极具竞争力。这使得 DeepSeek V3 成为开源 AI 领域中性价比极高的选择。

每个阶段的费用如下表所示:

那么,DeepSeek V3 究竟有何过人之处?它又是如何实现如此强大的性能的呢?接下来,我将为大家一一揭秘。
核心亮点一:更高效的架构
DeepSeek V3 在架构上延续了 DeepSeek-V2 的一些成功经验,并在此基础上进行了创新。
- Multi-head Latent Attention (MLA):为了实现高效的推理,DeepSeek V3 采用了 MLA 架构。MLA 的核心在于低秩联合压缩,通过压缩 attention 机制中的 key 和 value,来减少推理过程中所需的 KV 缓存,从而提升推理速度。
- DeepSeekMoE:为了实现更具成本效益的训练,DeepSeek V3 采用了 DeepSeekMoE 架构。与传统的 MoE 架构不同,DeepSeekMoE 使用更细粒度的专家,并将一些专家隔离为共享专家。这样做的好处是可以更灵活地分配计算资源,提高训练效率。
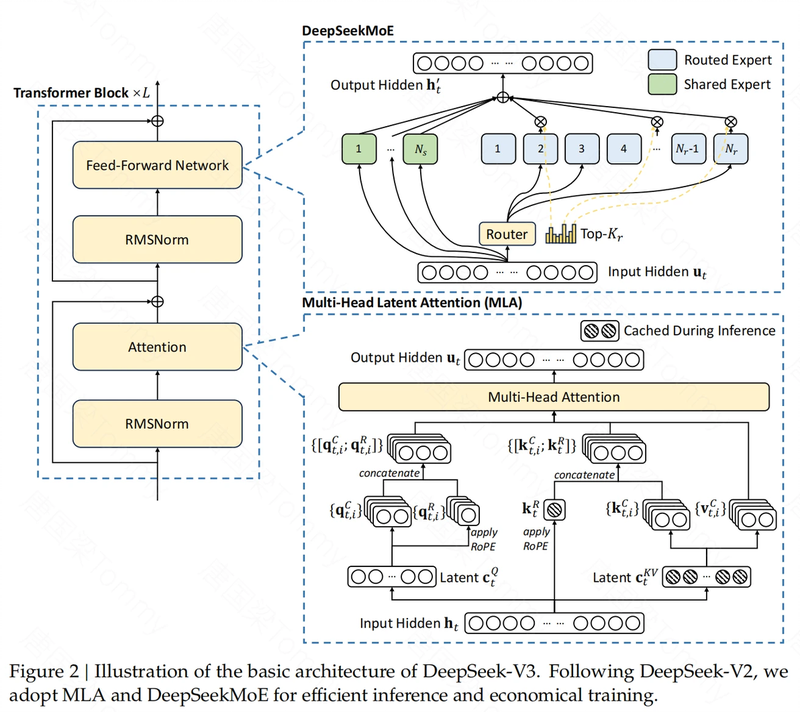
核心亮点二:无辅助损失的负载均衡策略
在 MoE 模型中,一个关键的挑战是如何平衡各个专家之间的计算负载。如果某些专家负载过高,而另一些专家却闲置,就会导致资源浪费和性能下降。DeepSeek V3 在这方面提出了一个非常巧妙的解决方案——无辅助损失的负载均衡策略。
- 无需额外损失函数:传统的 MoE 模型通常使用辅助损失函数来鼓励各个专家之间的负载均衡。但 DeepSeek V3 无需额外的辅助损失函数,而是通过巧妙地设计路由机制和门控值的计算方式,让模型在训练过程中能够自发地实现负载均衡。
- 专家亲和度:DeepSeek V3 通过专家亲和度 (token-to-expert affinity) 机制来实现隐式负载均衡。每个 token 会根据其内容与各个专家的亲和度来动态选择激活的专家。通过这种方式,模型自然地会将不同类型的 token 分配给最合适的专家。亲和力计算: 每个 token 通过 Sigmoid 函数计算其与路由专家的亲和力得分。选择 Top K 专家: 选择亲和力得分最高的 K 个路由专家。门控值计算: 通过对选择的亲和力得分进行归一化,得到最终的门控值。
- 自适应负载均衡:模型倾向于选择那些能够最大化其性能的专家,从而在训练过程中自动实现负载均衡。
- 专家专业化:该策略使得不同的专家倾向于处理不同领域或类型的输入,从而提高了模型的整体性能。
- 互补的序列级损失:为了防止极端不平衡,DeepSeek V3 也加入了一个互补的序列级平衡损失,但其贡献很小,主要机制仍是无辅助损失的负载均衡策略。
核心亮点三:多 Token 预测 (MTP) 训练目标
为了进一步提高模型的训练效率和性能,DeepSeek V3 引入了多 token 预测 (Multi-Token Prediction, MTP) 训练目标。
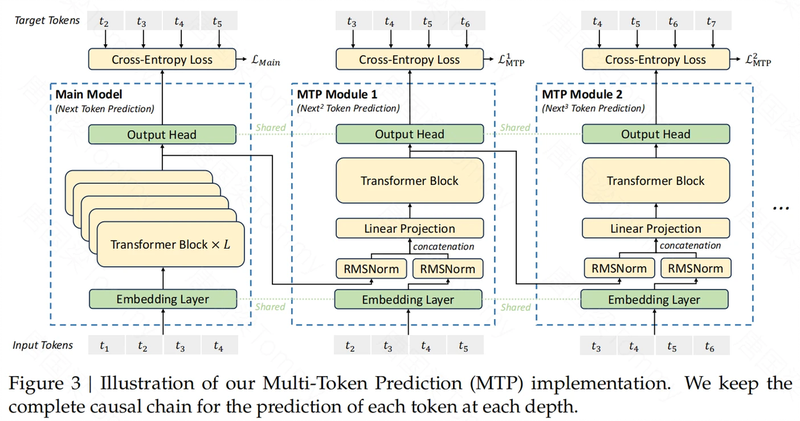
- 扩展预测范围:与传统的单 token 预测 (next-token prediction) 目标不同,MTP 扩展了预测范围,使得模型在每个位置能够预测多个未来的 token。
- 密集化训练信号:通过预测多个 token,MTP 增加了训练信号的密度,这意味着模型可以从每个训练样本中学习到更多信息。
- 提升模型预规划能力:MTP 使得模型能够预先规划其表示,更好地预测未来的 token,从而提高模型在各种评估基准上的整体性能。
- MTP 模块:MTP 的实现依赖于顺序连接的 MTP 模块,每个模块负责预测不同深度的未来 token。每个 MTP 模块包括一个共享的嵌入层 (Embedding Layer)、一个共享的输出头 (Output Head)、一个 Transformer 块 (Transformer Block) 和一个线性投影矩阵 M。
- MTP 训练目标:对于每个预测深度 k,计算一个交叉熵损失:
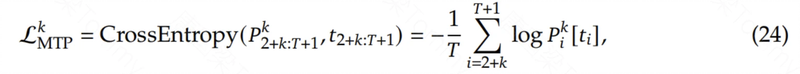
- 将所有深度上的 MTP 损失取平均值,并乘以一个权重因子,得到总的 MTP 损失:

- 将 L_MTP 作为额外的训练目标,用于优化 DeepSeek-V3 模型。
- 推理阶段的应用:在推理阶段,MTP 模块可以被直接丢弃,主模型可以独立正常工作。MTP 模块还可以被用于推测解码,进一步提高生成延迟,在保持生成质量的前提下,加快生成速度。
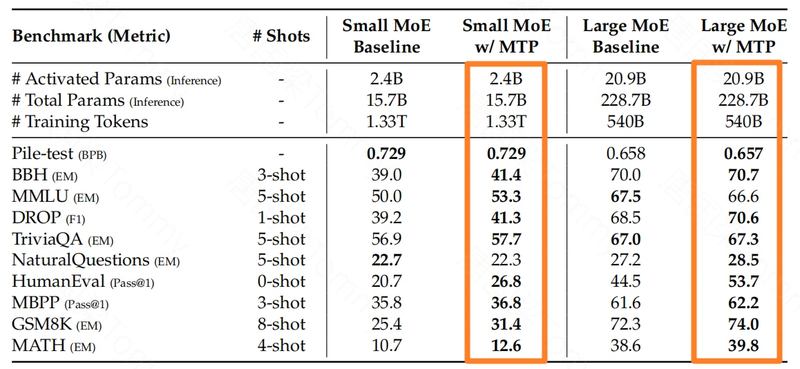
- 优势总结:MTP 策略在不同规模的模型上都能一致地提高性能。通过 MTP 技术,DeepSeek-V3 预测的第二个 token 的接受率在 85% 到 90% 之间,并且可以达到 1.8 倍的 TPS (Tokens Per Second),这证明了该方法的可靠性。
核心亮点四:高效的训练框架与基础设施
除了架构上的创新,DeepSeek V3 在训练框架和基础设施上也进行了大量的优化,从而实现了高效的训练。
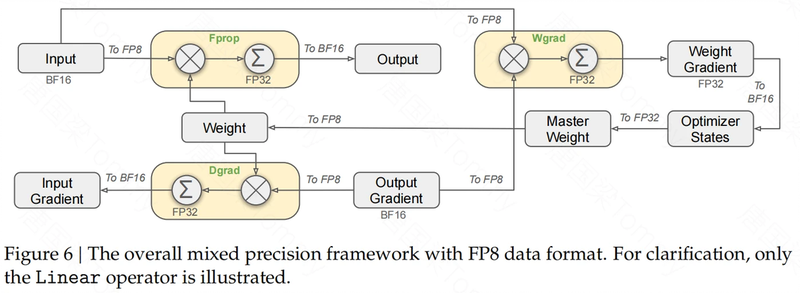
- FP8 混合精度训练:DeepSeek V3 采用了FP8 混合精度训练框架,这是一种低精度训练方法,可以在保持模型性能的同时,显著减少 GPU 内存使用和加速训练过程。
- DualPipe 算法:DeepSeek V3 设计了 DualPipe 算法,用于高效的流水线并行。DualPipe 不仅可以减少流水线的气泡,还可以重叠计算和通信过程,从而解决跨节点专家并行带来的通信开销问题。
- 高效的跨节点通信:为了充分利用 InfiniBand (IB) 和 NVLink 带宽,DeepSeek V3 开发了高效的跨节点全互连通信内核。通过限制每个 token 最多发送到 4 个节点,并结合 NVLink 的高速特性,实现了 IB 和 NVLink 通信的完全重叠。
- 内存优化:DeepSeek V3 在训练过程中,通过精心的内存占用优化,实现了无需昂贵的张量并行 (Tensor Parallelism, TP) 也能进行大规模模型训练。
- 硬件建议:基于 DeepSeek V3 的实现经验,论文还对 AI 硬件供应商提出了芯片设计的建议,例如专门为 AI 通信优化的硬件。

核心亮点五:高质量的预训练和后训练
为了保证模型的性能,DeepSeek V3 在预训练和后训练阶段都进行了精心设计。
- 高质量预训练数据:DeepSeek V3 的预训练数据包含了 14.8 万亿个高质量和多样化的 token,包括了数学和编程样本,以及多语言数据。采用了 Fill-in-Middle (FIM) 策略,使模型可以预测文本中间的内容。使用 Byte-level BPE 分词器,词汇表大小为 128K。
- 长上下文扩展:DeepSeek V3 采用了类似于 DeepSeek-V2 的方法,通过 YaRN 技术进行上下文扩展,将最大上下文长度扩展到 128K。
- 监督微调 (Supervised Fine-Tuning, SFT):DeepSeek V3 使用了包含 150 万个实例的指令调整数据集,涵盖了多个领域。对于推理相关的数据集,DeepSeek V3 使用 DeepSeek-R1 模型生成数据,并加入了反馈和验证机制。
- 强化学习 (Reinforcement Learning, RL):DeepSeek V3 采用了 Group Relative Policy Optimization (GRPO)算法进行强化学习,使用基于规则的奖励模型和基于模型的奖励模型来优化模型。在强化学习阶段,模型学习将 R1 模型的一些优秀特性融入到自己的能力之中。同时,DeepSeek V3 还采用了自奖励机制,利用模型自身的投票结果作为反馈源,进一步提升了模型的性能。
- 知识蒸馏:DeepSeek V3 通过从 DeepSeek-R1 系列模型中提取知识,显著提升了其在代码和数学等领域的推理能力。
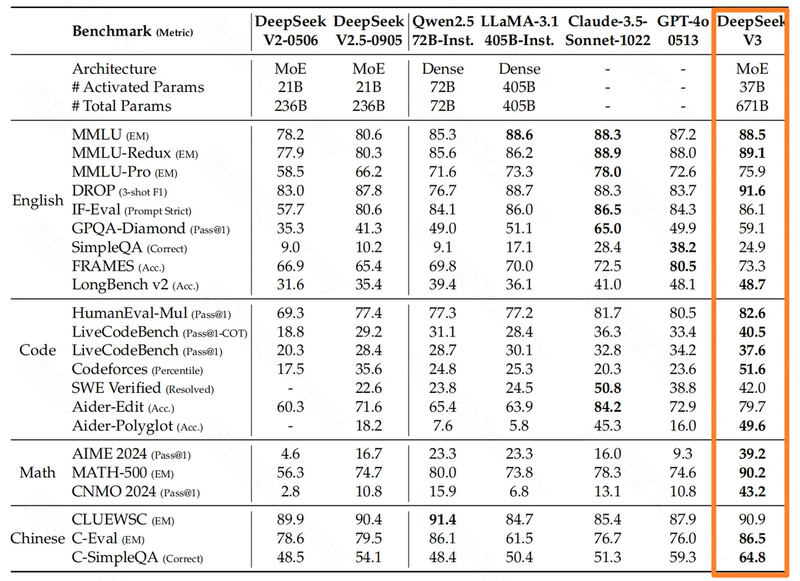
卓越的性能表现
DeepSeek V3 的综合性能表现非常出色。
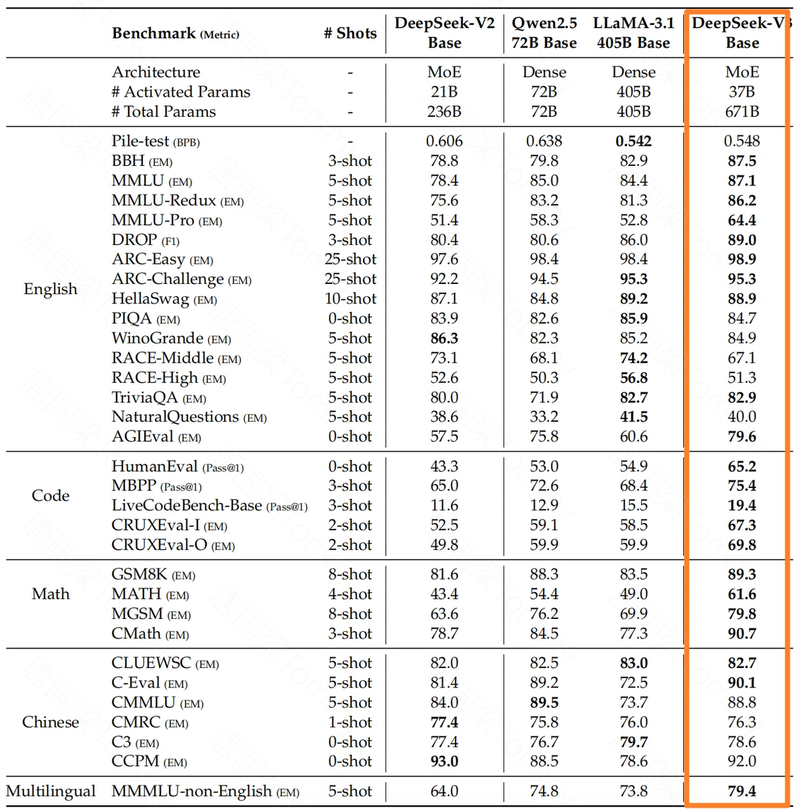
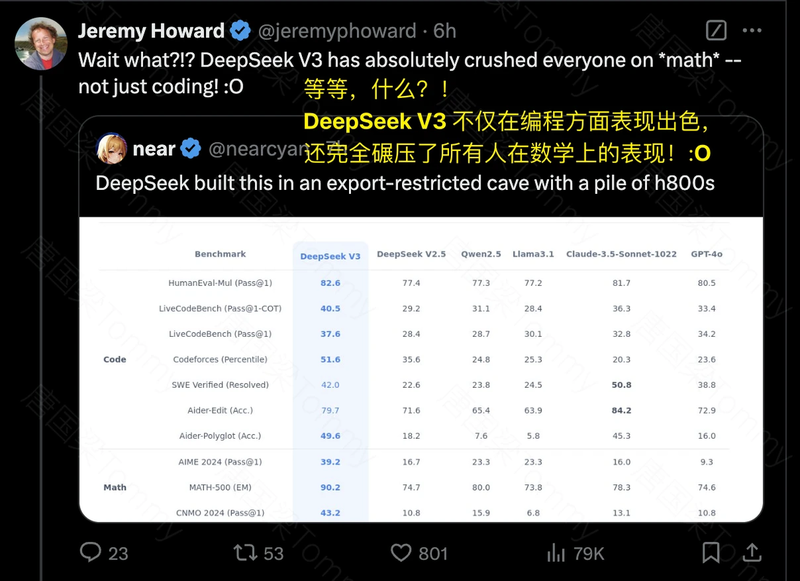
- 基模型性能:在 Pile-test, BBH, MMLU 等多个基准测试中,DeepSeek V3 的基模型都超过了其他开源模型,例如 DeepSeek-V2, Qwen2.5 和 LLaMA-3.1。尤其在代码和数学方面,DeepSeek V3 的基模型表现出了强大的优势。
- 对话模型性能:DeepSeek V3 的对话模型在 MMLU, GPQA 等标准基准测试中,都达到了 SOTA 水平,与 GPT-4o 和 Claude-3.5-Sonnet 等领先的闭源模型相媲美。在 LongBench v2, FRAMES 等长文本基准测试中,DeepSeek V3 也展现出了出色的性能,体现了其强大的长文本处理能力.在代码和数学基准测试中,DeepSeek V3 的表现也同样出色,尤其是在 AIME, MATH-500, CNMO 2024 等基准测试中,超过了其他模型。在开放式的评估中,DeepSeek V3 也超过了所有其他开源模型,并且可以与最先进的闭源模型相媲美。在 RewardBench 基准测试中,DeepSeek-V3 的表现可以与 GPT-4o 和 Claude-3.5-Sonnet 的最佳版本相媲美。
总结与展望
总的来说,DeepSeek V3 是一款非常强大的开源大模型,它在架构、训练、推理等多个方面都进行了创新,并在性能上取得了显著的提升。
- 架构创新:MLA 和 DeepSeekMoE 架构保证了高效的推理和训练。无辅助损失的负载均衡策略:无需额外的损失函数,实现了自适应的负载均衡。多 token 预测训练目标:提高了训练效率和模型性能,并为推理加速提供了潜力。高效的训练框架与基础设施:支持 FP8 训练,采用 DualPipe 算法,优化内存使用。高质量的预训练和后训练:保证了模型在知识、推理和长文本处理等方面的能力。卓越的性能表现:在多个基准测试中都达到了 SOTA 水平,与领先的闭源模型相媲美。
DeepSeek V3 的发布,无疑为开源大模型的发展注入了新的活力。虽然目前 DeepSeek V3 在部署方面仍然存在一些限制,例如推荐的部署单元较大,但随着硬件技术的进步,这些问题有望得到解决。DeepSeek 团队也表示,他们将继续在模型架构、训练效率、无限上下文长度等方面进行研究,力求在通往 AGI 的道路上不断前进。
总而言之,DeepSeek V3 的出现,不仅标志着开源大模型技术又迈上了一个新的台阶,也为我们提供了更多探索和利用 AI 的可能性。相信在未来,DeepSeek V3 将在学术研究、产业应用等多个领域发挥重要作用。
参考文献
本文章基于以下论文内容整理和总结:
论文名称: DeepSeek-V3 Technical Report
发表日期: 2024年12月26日
原文链接: https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
GitHub:https://github.com/deepseek-ai/DeepSeek-V3.git

你好,我是唐国梁Tommy,专注于分享AI前沿技术。
欢迎你加入我的精品课程《深入LLM与RAG 原理、实现与应用》。本课程将为你提供深入的理论知识与实践操作,帮助你深刻理解并熟练运用主流的大语言模型(LLM)和检索增强生成(RAG)。
你将学习如何构建和部署独立的Embedding模型服务,用于计算文本查询的向量嵌入;此外,我还将带你完成两个完整的Chatbot项目实战:FAQ-Chatbot(自研项目)和 LangChain-Chatchat(整合了自研Elasticsearch知识库功能)。
我的所有精品课程永久有效,并会适时更新,让你真正实现终身学习。本课程已在我的个人网站完成更新,点击以下卡片了解更多,更多精品课程信息请访问我的个人网站:TGLTommy.com
