一夜之间,DeepSeek突然之间炸场,各个大佬都在纷纷转发,而且发布即开源,直接用50多页的论文公布了其训练细节
简单来说,DeepSeek V3是个拥有671B参数的MoE模型,每个token可以激活37B参数,利用了大概14.8T的高质量token进行了大规模与训练。原生就是FP8混合精度训练框架,并首次验证其在超大规模模型上的有效性
训练大模型也可以很省钱
DeepSeek V3延续了便宜又快的训练思路。
DeepSeek V3的训练总共才用了不到280万个GPU小时,而Llama 3 405B却用了3080万GPU小时。用训练一个模型所花费的钱来说,训练一个DeepSeek V3只需要花费557.6万美元,相比之下,一个简单的7B Llama 3模型则需要花费76万美元。
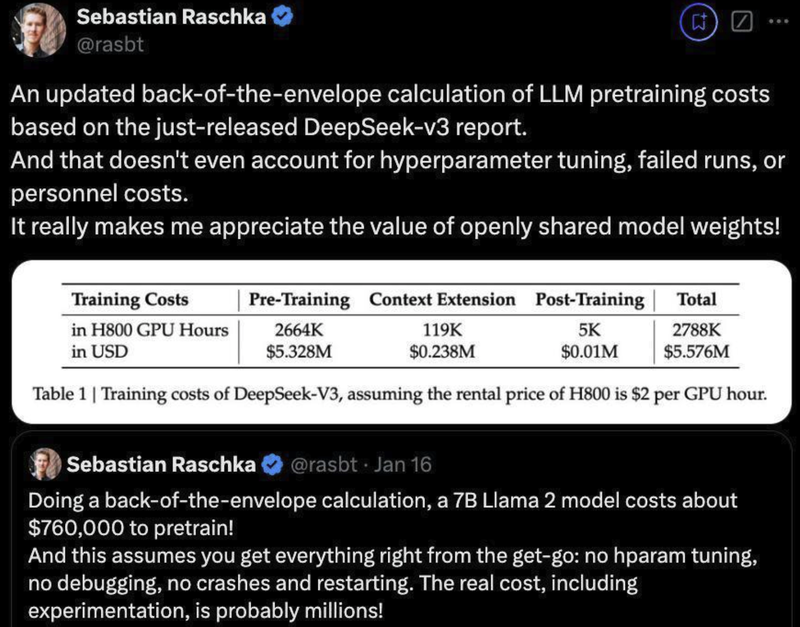
从论文中的公布细节可以得到它的训练成本估算:
- 以 H800 GPU 小时为单位。H800 GPU 的租赁价格假定为每小时 2 美元。训练分为三个阶段:预训练、上下文扩展和后期训练:预训练:使用了 2664K(266.4 万)GPU 小时,成本约为 532.8 万美元。上下文扩展:使用了 119K(11.9 万)GPU 小时,成本约为 23.8 万美元。后期训练:使用了 5K GPU 小时,成本约为 1,000 美元。总成本:2788K(278.8 万)GPU 小时,总费用为 557.6 万美元。
比起动辄几百亿人民币都训练不出来一个好用的大模型,DeepSeek V3的训练简直颠覆了大家的想象。这里训练这么省钱当然主要是因为该模型原生就是FP8,还有在模型架构上做了一些优化导致模型训练成本很低。
模型效果惊为天人
从发布的效果来看,这个开源模型在多个数据集上的效果都能够赶上最前沿的几个大模型。
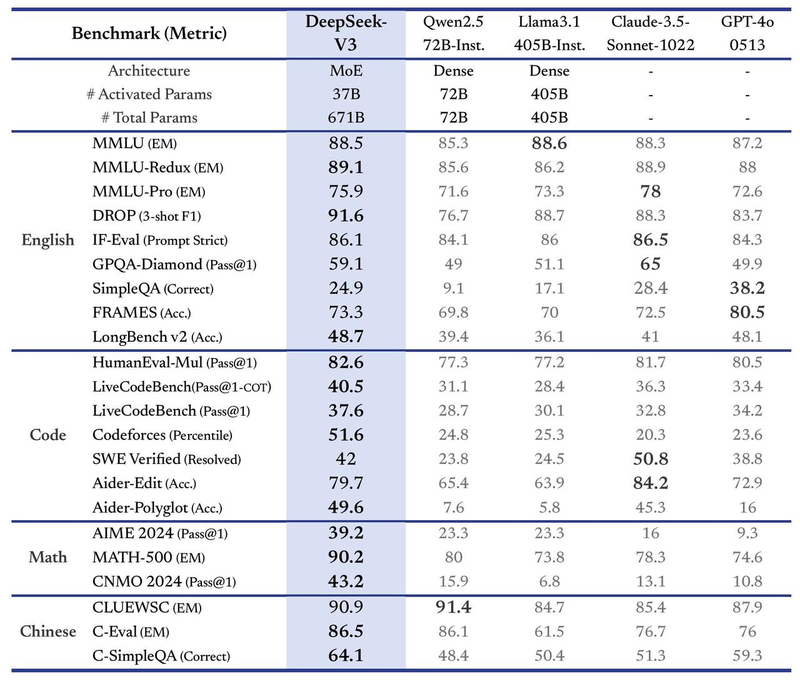
比如在英语任务上,在多项英语基准(MMLU、MMLU-Redux、DROP 等)上,DeepSeek V3 展现了强劲的性能:在 MMLU-Redux(89.1)和 DROP(91.6)的表现优于其他模型,就连GPT-4o分数都比它要低,在复杂推理任务中展现了领先优势。F-Eval(Prompt Strict)上达到 86.1,仅仅只略低于 Claude-3.5(86.5)。
在编程领域上,DeepSeek V3 在编程任务中表现中规中矩:
- 在 HumanEval-Mul 和 Codeforces 的基准上,分别取得 82.6 和 51.6。对比之下,只有Claude-3.5 在部分代码生成任务上(SWE Verified)表现略优。
在数学任务上,DeepSeek V3 在数学推理任务中表现出色:
- MATH-500(90.2)的表现超过 GPT-4o(74.6)和 Claude-3.5(78.3)。在 AIME 2024 和 CNMO 2024 的 测试中,分别取得 39.2 和 43.2 的分数。
中文任务这个应该是最有优势的了,基本都可以秒杀国外的一些前沿大模型,
- CLUEWSC(90.9)接近 Qwen2.5 的顶级表现(91.4)。在更复杂的中文问答任务(C-SimpleQA)中,DeepSeek V3 的分数为 64.1,达到顶尖水准。
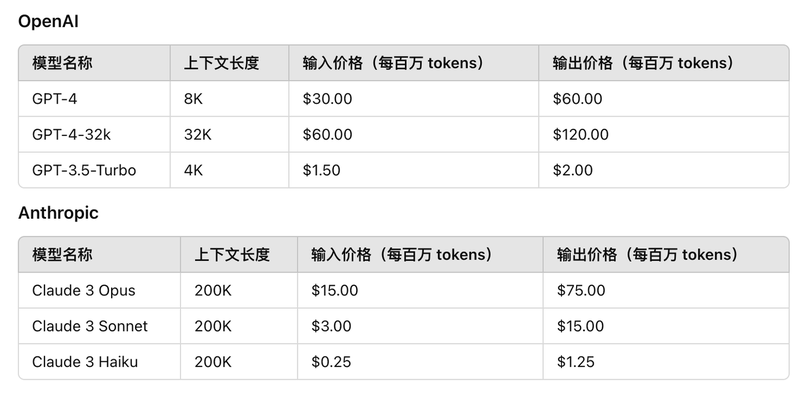
在又快又好的同时,DeepSeek V3的API价格也被打下来了。每一百万的输入tokens,只需要0.27 ;每百万的输出 t o k e n s 需要 1.1 ;每百万的输出tokens需要1.1 ;每百万的输出tokens需要1.1。
我们这里对比一下目前国外几个前沿大模型的价格,**GPT-4每百万输入tokens,高达30 ,而 C l a u d e 3 O p u s 每百万输出 t o k e n s 也要 15 ,而Claude3 Opus每百万输出tokens也要15 ,而Claude3Opus每百万输出tokens也要15。**从价格上来看,DeepSeek V3真的是太便宜的,便宜到我都怀疑这个公司还能不能赚到钱。
而如果要平衡性能和成本,它就成了DeepSeek官方绘图中唯一进入“最佳性价比”三角区的模型。其他像GPT-4o、Claude3.5等模型,价格都比较昂贵。
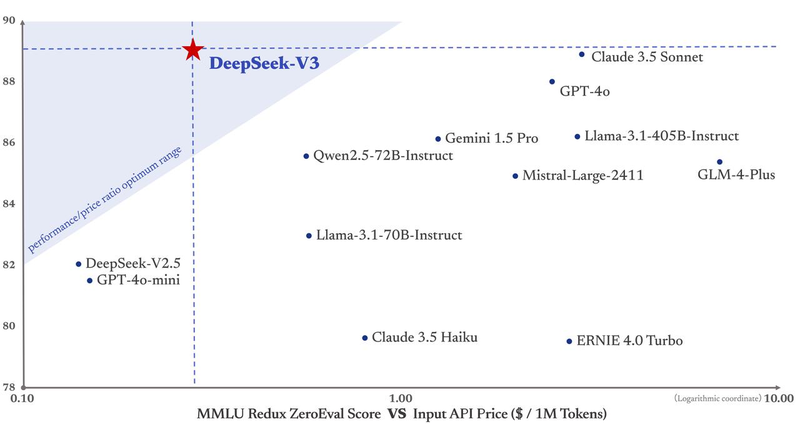
模型的一些训练细节
DeepSeek V3除了使用了FP8之外,还有一些其他的模型细节。比如它继续采用了多头潜在注意力(MLA)来实现高效推理。它在传统多头注意力机制(Multi-Head Attention)的基础上,引入了潜在特征(Latent Features)概念,进一步提高了对复杂关系的建模能力。
也就是先把token的特征压缩成一个小维度的latent vector,然后再通过一些简单的变换把它扩展到各个头需要的Key和Value空间。对于一些重要的信息,比如旋转位置编码RoPE,会进行单独处理,这样网络仍然可以保留时间和位置的信息。
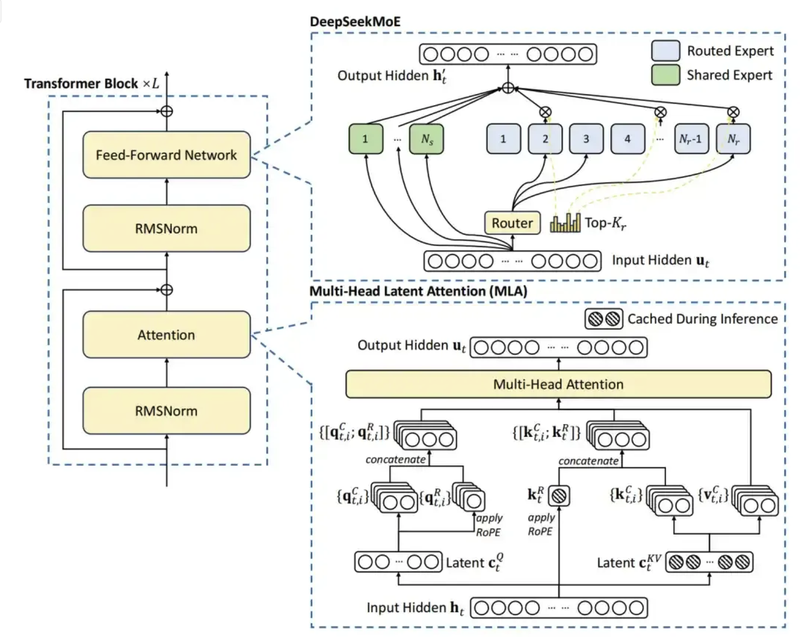
在MOE架构中,引入了路由专家 (Routed Experts) 和共享专家 (Shared Experts) 。主要是用来激活那些参数需要被更新。
**路由专家中主要是用来选择参数进行激活。**对于每个输入的token,只有一部分路由专家会被选中来参与计算。这个选择过程是由一个门控机制决定的,比如DeepSeekMoE中用的那种根据亲和度分数来选的Top-K方式。
而**共享专家始终参与所有输入的处理。**无论输入是什么,所有共享专家都会贡献它们的力量。
还用到了一个MTP(多个tokens预测)技术,**MTP的核心理念在于训练时,模型不仅要预测下一个token(就像传统语言模型那样),还要同时预测序列后面的几个token。**这样一来,模型就能获得更丰富的训练信息,有助于它更深入地理解上下文以及长距离的依赖关系。

写在最后
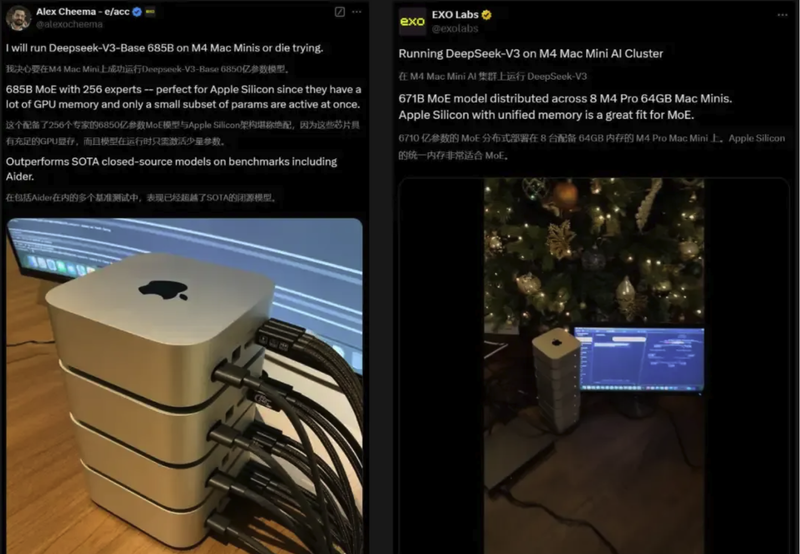
DeepSeek-V3现在已经可以在官方平台上直接测试了,代码也是完全开源的,可以随时下载。国外的AI爱好者们都已经开始尝试了,有人甚至把4个或8个M4 Mac mini叠在一起运行DeepSeek V3。
还有开发者用DeepSeek-V3创建了一个AI公司logo风格的小行星游戏,只要几分钟很快就搞定了。
如何系统的去学习大模型LLM ?
AI会取代那些行业谁的饭碗又将不保了?
抢你饭碗的不是AI,而是会利用AI的人。
科大讯飞、阿里、华为
与其焦虑……
掌握AI工具的技术人
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础 第二不要求准备高配置的电脑 第三不必懂Python等任何编程语言
LLM大模型资料LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程
👉CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)👈

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。
二、640套LLM大模型报告合集
三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程
LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。 内容: L1.1 人工智能简述与大模型起源L1.2 大模型与通用人工智能L1.3 GPT模型的发展历程L1.4 模型工程L1.4.1 知识大模型L1.4.2 生产大模型L1.4.3 模型工程方法论L1.4.4 模型工程实践L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。 内容: L2.1 API接口L2.1.1 OpenAI API接口L2.1.2 Python接口接入L2.1.3 BOT工具类框架L2.1.4 代码示例L2.2 Prompt框架L2.3 流水线工程L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。 内容: L3.1 Agent模型框架L3.2 MetaGPTL3.3 ChatGLML3.4 LLAMAL3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。 内容: L4.1 模型私有化部署概述L4.2 模型私有化部署的关键技术L4.3 模型私有化部署的实施步骤L4.4 模型私有化部署的应用场景
LLM大模型资料LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程
👉CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)👈