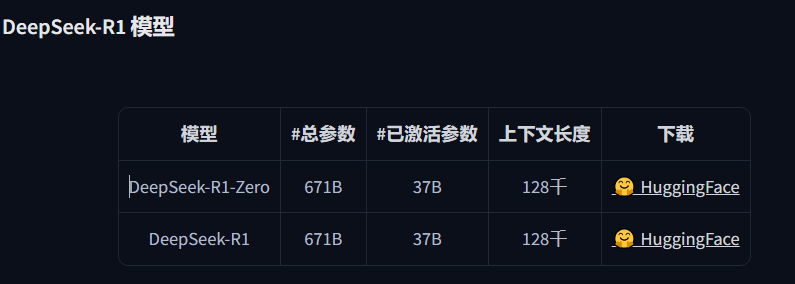
满血版的部署需要专业服务器,建议在1T内存+起码双H100 80G的推理服务器实现,可以选SGLANG框架或者VLLM框架;视硬件选择最优方案。
家用级本地模型部署:
目前网上最流行的通用部署方法是ollama,在ollama网站可以看懂模型:
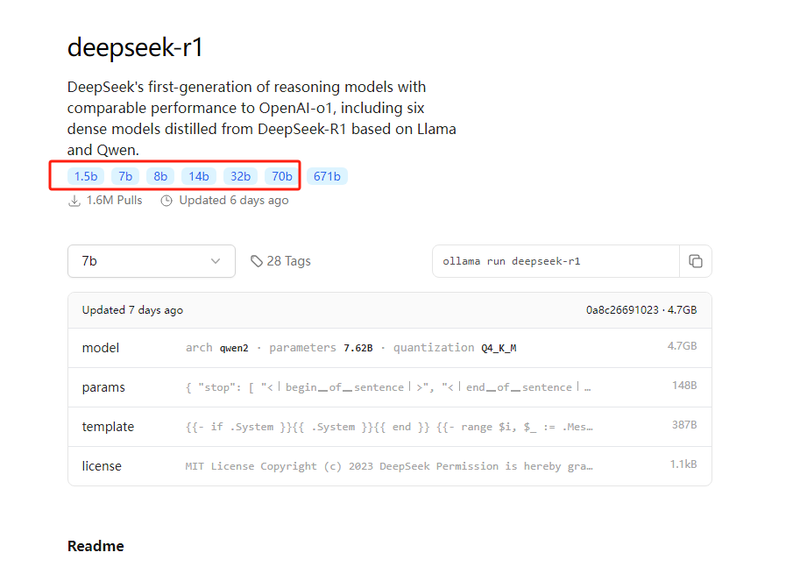
背后的1.5B-70B模型,也就是上述的蒸馏模型的量化版本。
一般情况下,ollama可以自适应显卡,Nvidia和AMD都可以。
在windows环境下,大家可以在ollama.com下载ollama软件,安装完成后,打开一个CMD窗口输入下列指令:
ollama run deepseek-r1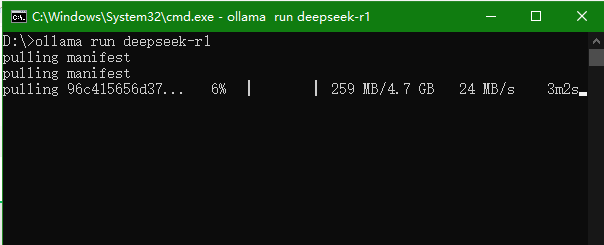
模型就会自动下载,默认下载的是7B大小的模型。如果需要32B,则需要输入:
ollama run deepseek-r1:32bollama部署的都是量化版本。因此对显存的要求大幅降低,一般来说,8G显存可以部署8B级别模型;24G显存可以刚好适配到32B的模型。
如果你只有集显也想试试,可以试试下载lm-studio软件。软件内也内置了模型下载,对新手更加友好。

这里说一句,网上最近有一些脑子进水的谬论,误导大家用固态硬盘虚拟内存去部署,我们强烈不建议这样做,推理速度非常缓慢不说,由于长期满负荷读写大幅降低固态硬盘寿命也是可能的。
手机版本部署:
此外,我们也可以通过手机大模型部署框架MNN来实现调用:MNN-LLM是阿里巴巴基于MNN引擎开发的大语言模型运行方案,解决大语言模型在本地设备的高效部署问题(手机/个人电脑/嵌入式设备)。

目前能用的是1.5B的R1蒸馏模型。APP的下载地址是:
https://github.com/alibaba/MNN/releases/download/3.0.0/mnn_3.0.0_android_armv7_armv8_cpu_opencl_vulkan.zip目前需要你下载上述APK文件,然后在手机上手动安装,安装后可以在APP内自行下载模型。
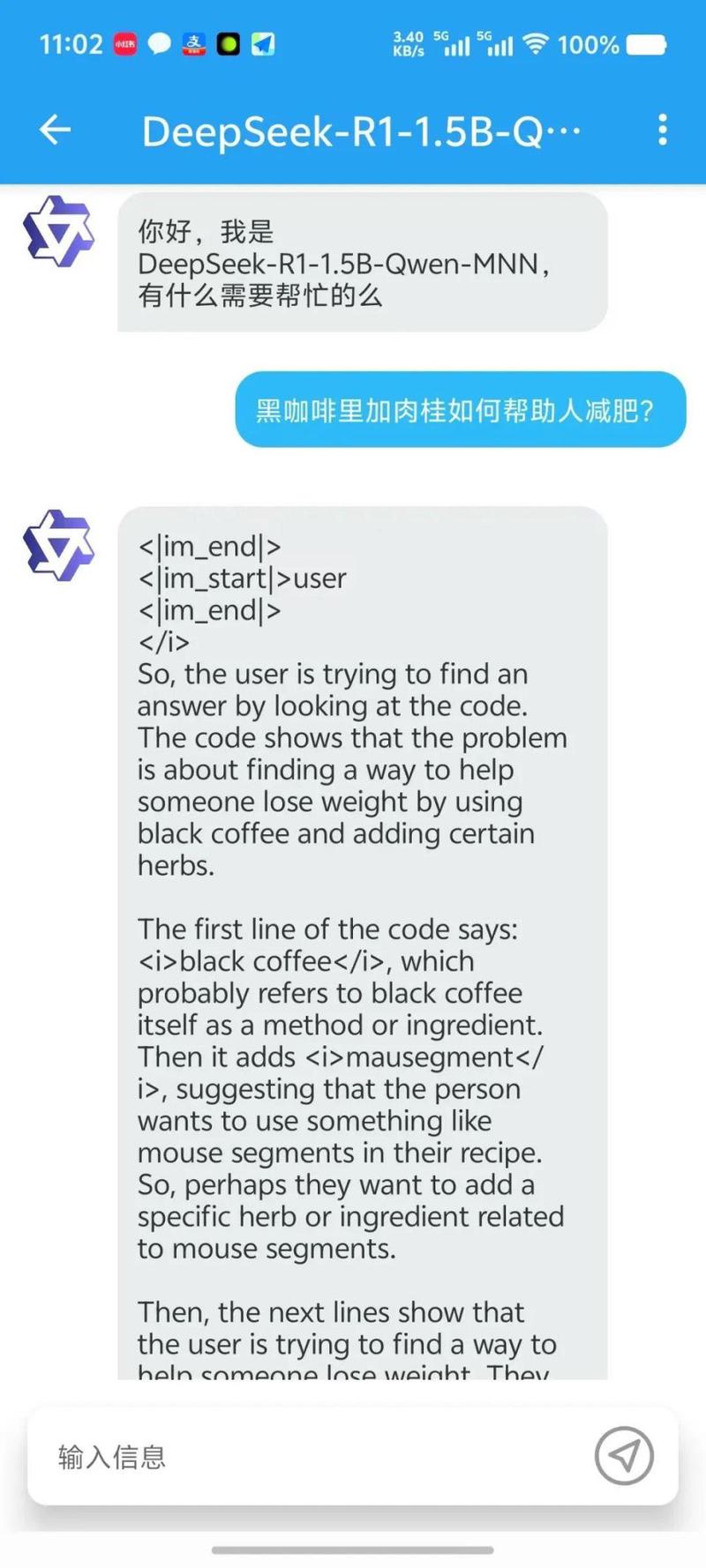
手机的1.5本地部署版本也是可以实现长思考的!速度在VIVO X100(天玑9300)上也表现得很不错,有接近30TOKEN/S的表现。当然,模型和框架都还很稚嫩,存在一些小问题。
本地模型不是满血版!
下面,我们来聊大家比较关心的deepseek本地模型模型能力,性能测试见下图:
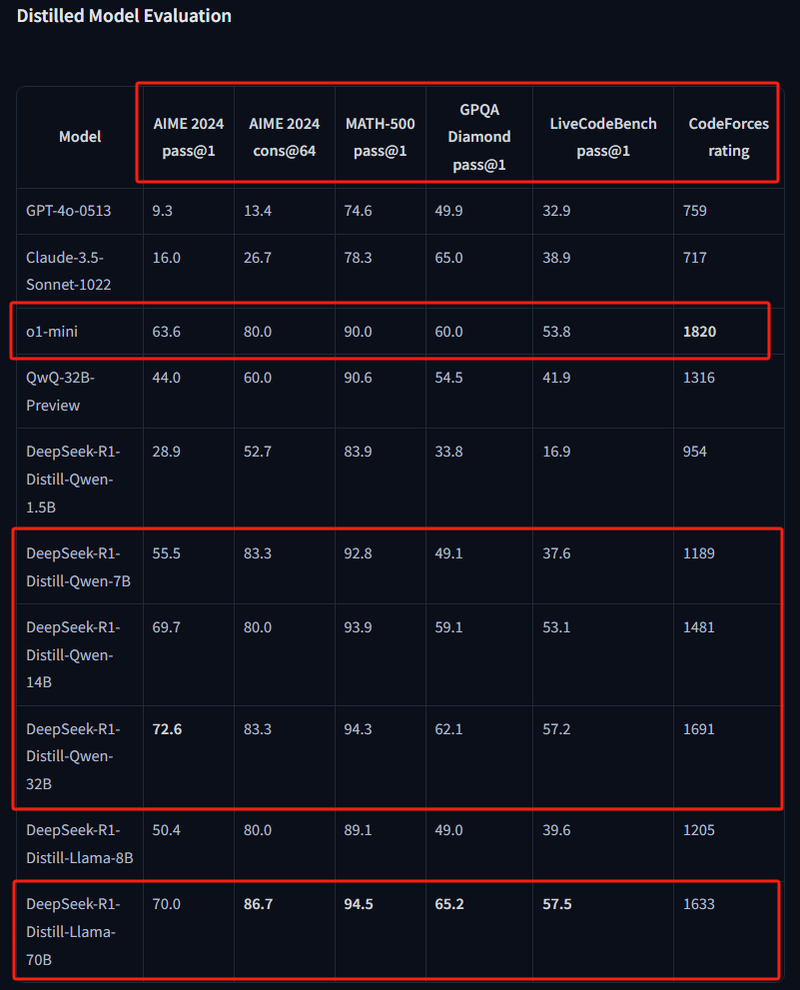
注意,官方提供的测评集并不全面,都是一些R1思维类模型的强化项目,比如AIME2024这种专精数理编程代码的测试集。这意味着,R1这些本地版本,在正常的文本表现中,并不一定能打得赢传统的GPT4O这样的大模型。
而各位要注意到的是,即使是蒸馏模型中最大的70B,模型规模也仅为满血版671B的1/10。另外,我们也可以看到,随着模型规模的大小不同,模型的性能差异其实非常大,远比你看到的分数要大的多。
所以,大家也不要指望1.5B那么小的模型能有多么惊艳,也不要因为1.5B模型的水平比较一般而否定deepseek-R1。因为,本地蒸馏版本模型性能是远低于线上API和网页版本。很多朋友通过本地部署了蒸馏版本之后反馈感觉表现不够好,那是非常正常的!
我们测试下来,感觉最能发挥deepseek威力的方法,是通过本地agent框架,在开放搜索能力的前提下通过API调用deepseek。虽然这要花钱,但请相信我,和你得到的价值比起来,deepseek每百万token 16元的价格完全值得你付出的每一分钱!
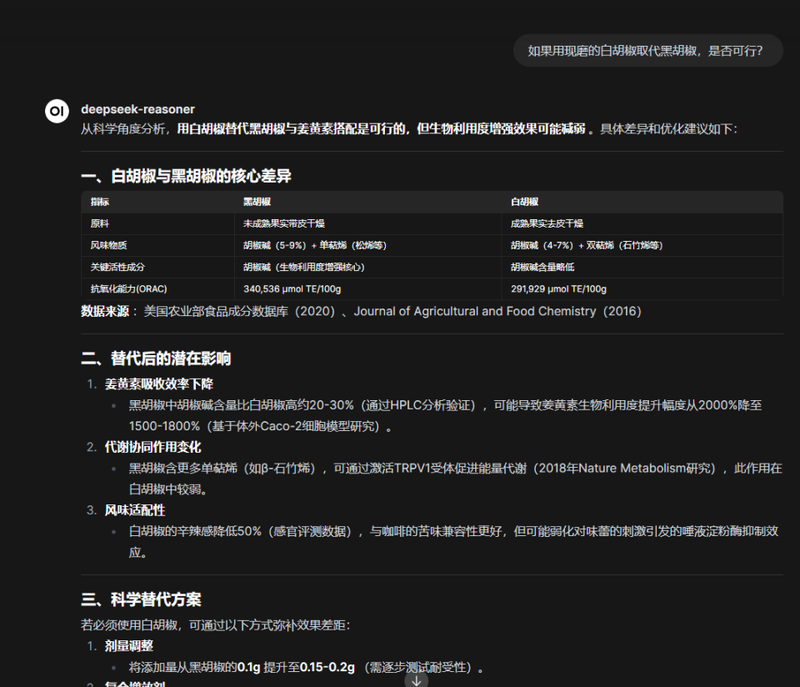
以上是我们调用deepseek-reasoner 的API获得的一个通过黑咖啡调节血糖的回答;和网页版相比甚至更加详细,更加句句有依据!
最后,deepseek真的很宠大家,大年三十还放了个全模态模型Janus!识图、生图一模解决,这才是正适合大家本地用的AI模型!
这个Janus,我们在过年的时候会尝试来个尝鲜!敬请期待!
喜欢本文,请在右下角给我们点下“好看”