
教程作者: 野鹿志(授权转载)
交作业:微博搜索话题 #优设每日作业# 进入话题页即可发布作业
一、关于教程
其实一直以来,我觉得分享式的学习方法特别适合我。在学习的过程中,分享出来,相当于对自己学到的内容进行进一步的梳理和巩固。
前面连续两篇文章,我们分别分享了SD的软件安装、文生图的概述、Ai绘图初体验以及模型的分类。
今天我打算将文生图的内容补充完整,着重分享一些之前没分享过的知识点。我相信通过这三篇连续的文章分享,新手在文生图方面基本上可以算是入门了。
二、教程内容
#01 Clip跳过层
Clip跳过层我们一般很少调整,但为了完整性还是大概说明一下它的作用。
这里先说一下测试出来的结论:数值越高,生成的图和提词的相关性越低。
例如,在提词器中设置了关键词杰尼龟、可爱、帽子、水,接下来需要找一个不错的状态来固定随机种子:
这里我用XYZ图表脚本生成了一个对比图,关于XYZ图表的使用我们以后再说:
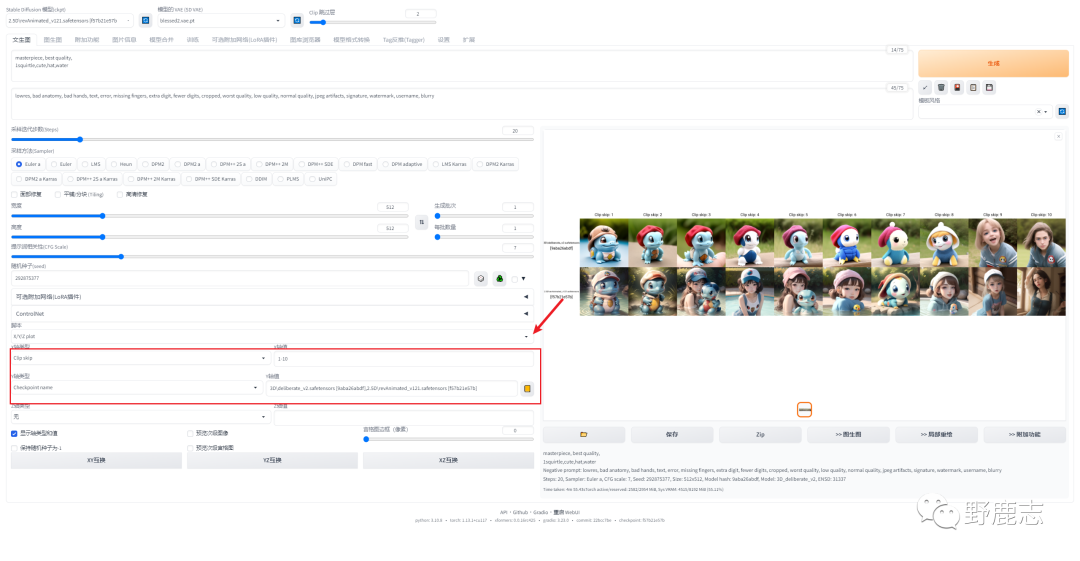
横向对比是Clip跳过层从1-10,纵向对比了两个模型,可以观察到,总的来说数值越高,得到的图像就越缺少我们在提词器中设定的内容:

这一点我觉得我们新手仅作了解就好,大部分情况下Clip跳过层的数值保持默认即可。
#02 采样迭代步数
采样迭代步数在之前的文生图概述中已经提到过了,当鼠标停留在上面时,也可以看到它的含义:
简单来说,采样迭代步数就是用多少次来计算你提词器里的内容。
同样我这里设置了在1-40的步数范围内取其中10张图来做对比:
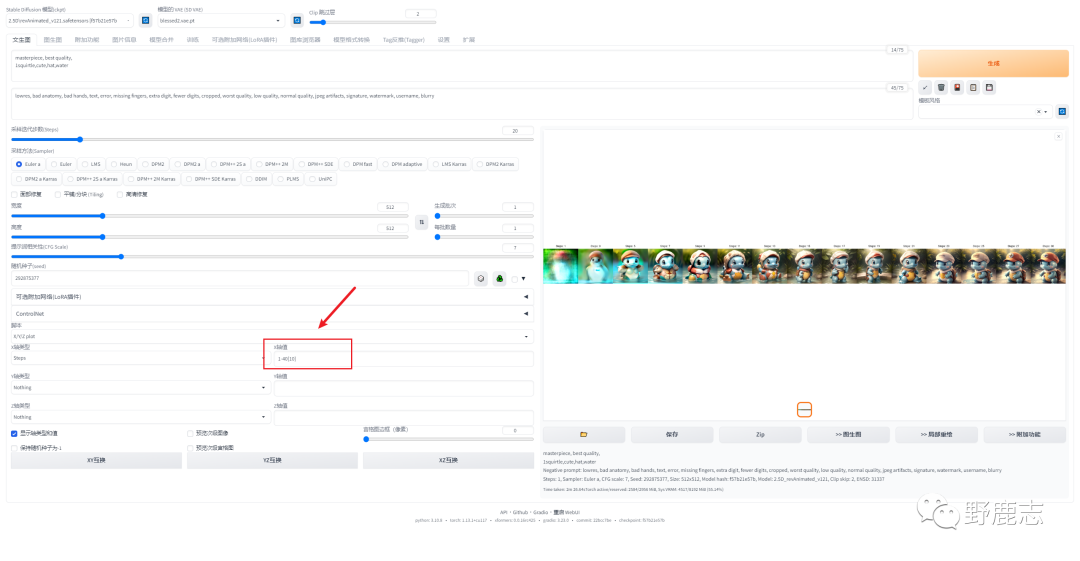
可以观察到,当步数太低时,生成的图像几乎无法呈现内容;个人认为,将步数控制在30以内比较合适,因为超过30步会增加生成图片所需的时间,但收益可能有限:

#03 采样方法
采样方法在之前已经提到过,它指的是不同的算法。在之前的采样迭代步数对比的基础上,我在上面增加了所有采样方法的对比,以便进行纵向比较:

从速度方面来看,DDIM的速度最快,而DPM Adaptive则较慢:

但是这个对比只能作为参考,因为不同的采样方法可能对不同的模型产生不同的影响。
因此,对于采样方法的选择,我认为最好的方法便是尝试,以及根据个人的喜好进行选择。
目前在网络上使用最广泛的几种采样方式分别是:Euler a、DPM++ 2M Karras、DPM++ SDE Karras、DDIM:

#04 面部修复、平铺及高清修复
面部修复通常用在生成三次元的图,例如我这里生成一个三次元的图,面部会有些崩坏:
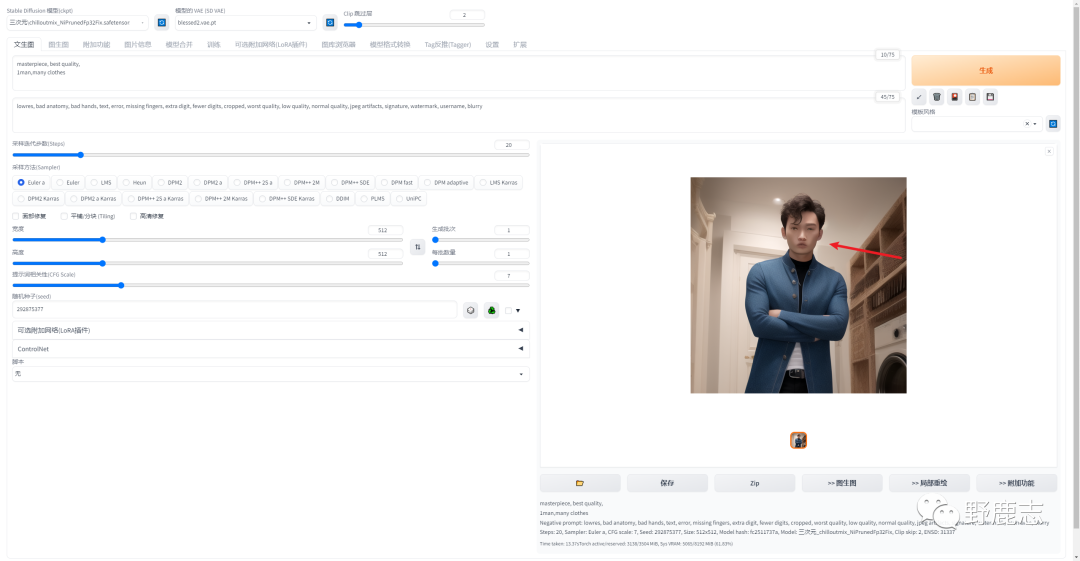
开启面部修复功能后,对于生成的三次元图像,崩坏情况可能会有一定改善。但对于二次元图像,建议不要开启面部修复功能:

平铺是用于生成花纹的,我没用过,这个咱们新手就暂时跳过吧:
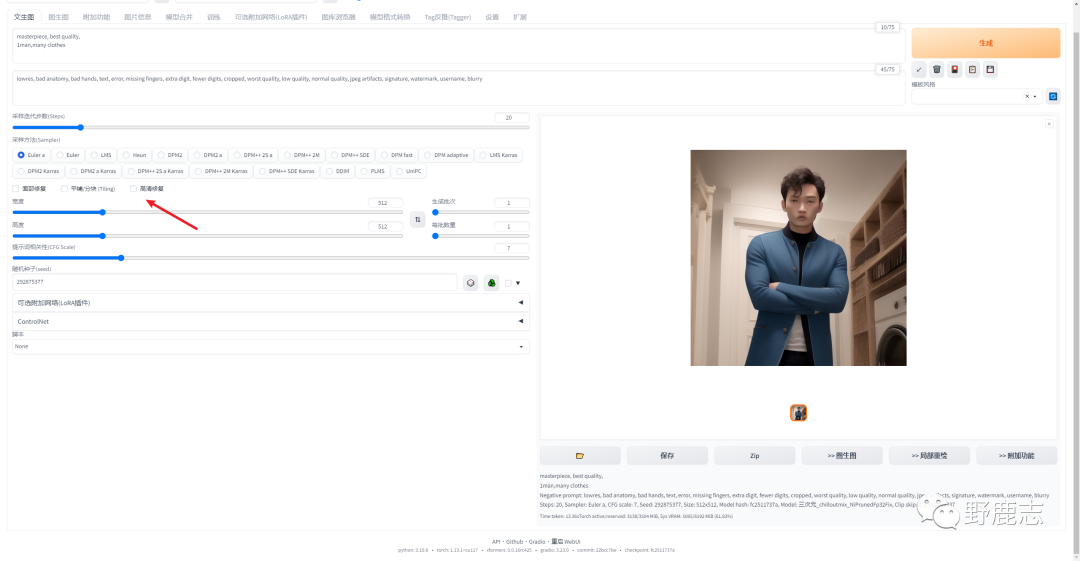
高清修复功能在一定程度上也可以帮助改善面部效果,例如我这里以男人的图为例进行演示:
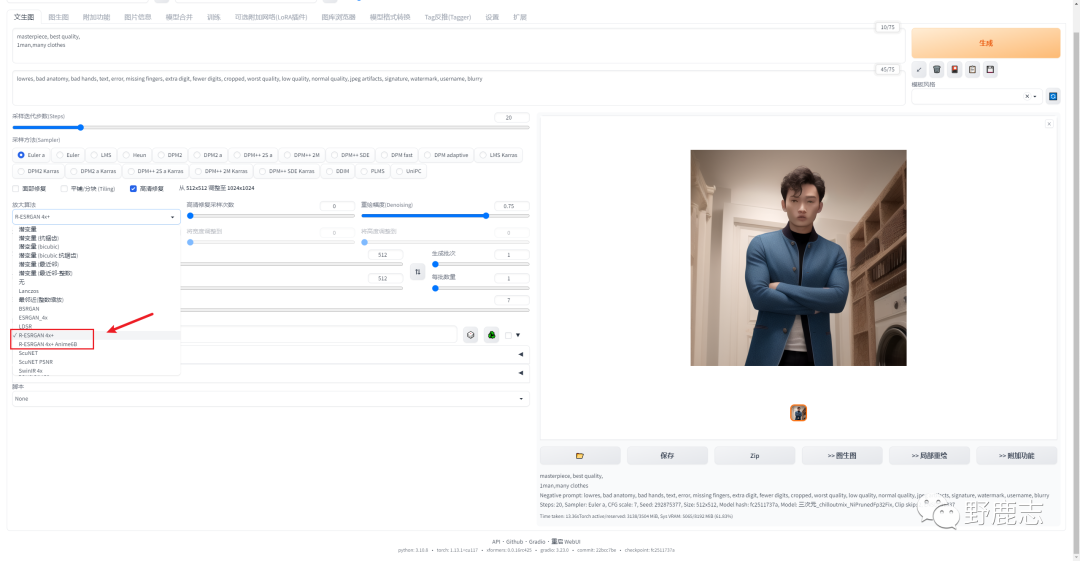
对于三次元图像,可以选择R-ESRGAN 4x+算法;对于二次元图像,可以选择R-ESRGAN 4x+ Anime6B算法。这两个算法在高清修复中通常会获得较好的效果:
通常情况下,高清修复的采样次数可以保持默认值为0,这样它会和采样迭代步数保持一致。
而重绘幅度数值越高,生成图像与原图的差异也会越大。一般情况下,0.4到0.7的效果都不错:
放大倍率顾名思义就是在原有分辨率的基础上放大多少,千万别给太高,否则显卡会崩,通常2倍就足够了:
可以看到面部得到了改善,并且由于我重绘幅度给的比较高,所以画面的变动比较大。
另外提示一点,当面部崩坏的时候,面部修复和高清修复二选一,不要两个都开,否则会适得其反:
#05 分辨率
分辨率的设置是尤为关键的,上一篇模型分类的文章中,我们提到了几乎所有的模型都是基于SD官方模型训练得来的。
而以官方模型sd1.5为例,训练时候图片的分辨率是512*512:
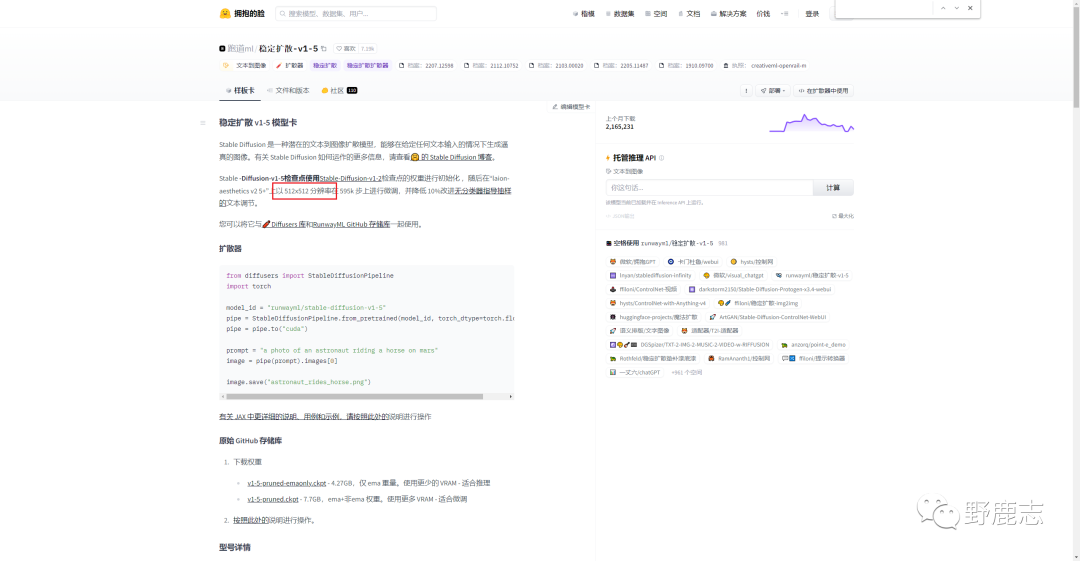
sd2.1的分辨率新增了768*768版本:

也就是说几乎所有的模型训练的尺寸都是512*512或者768*768。
因此当我们分辨率太低,例如低于256*256,会让SD没地方发挥,导致图像质量下降:
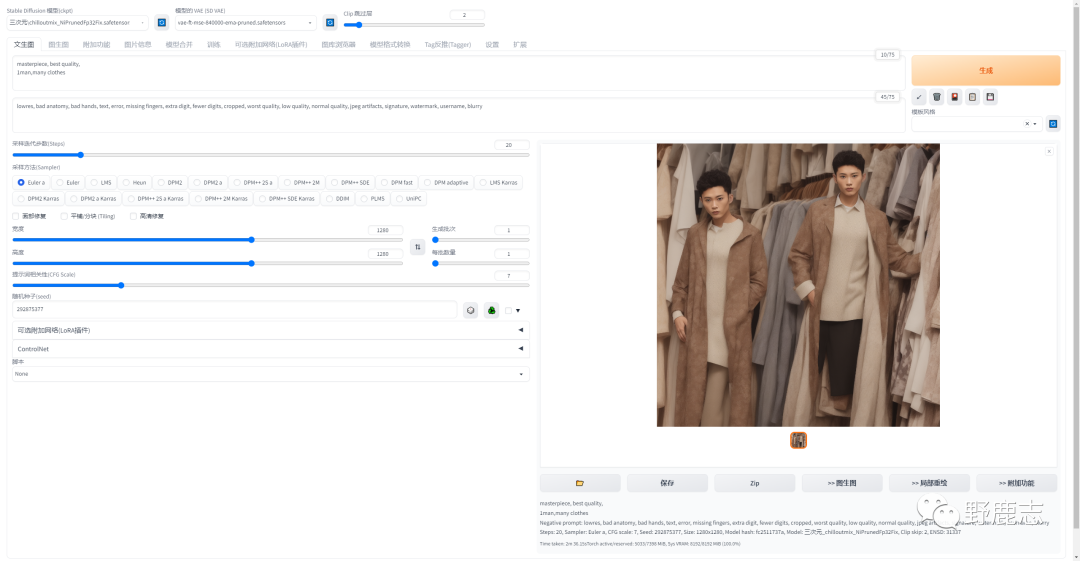
而当我们把分辨率设置过高,例如高于1024*1024,会让SD乱发挥,构图会有问题,甚至产生鬼畜效果:
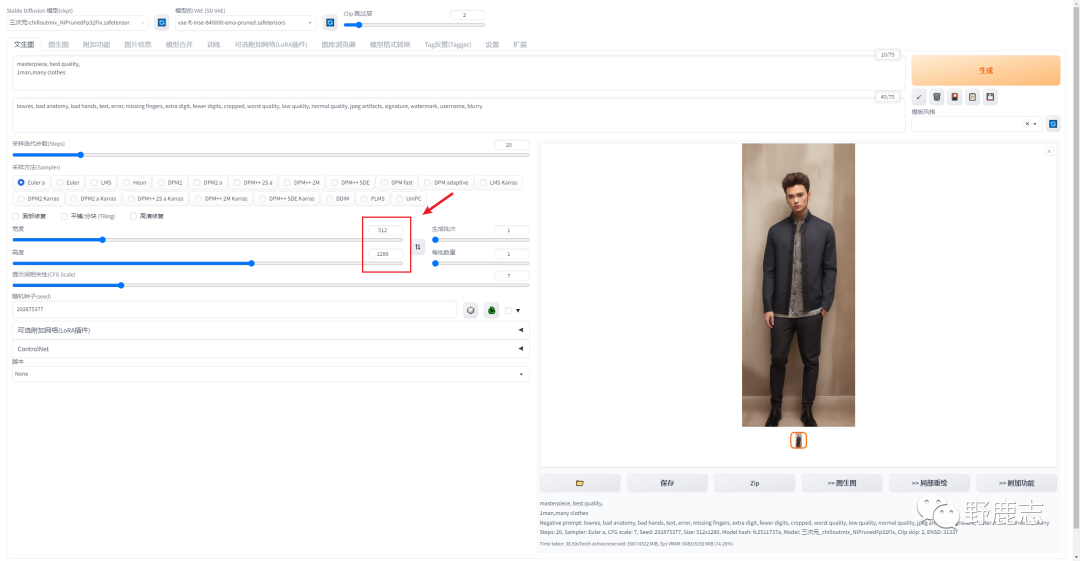
这个和宽高比没有关系,例如我把宽改为512,高保持1280也能生成一副正常的图片:
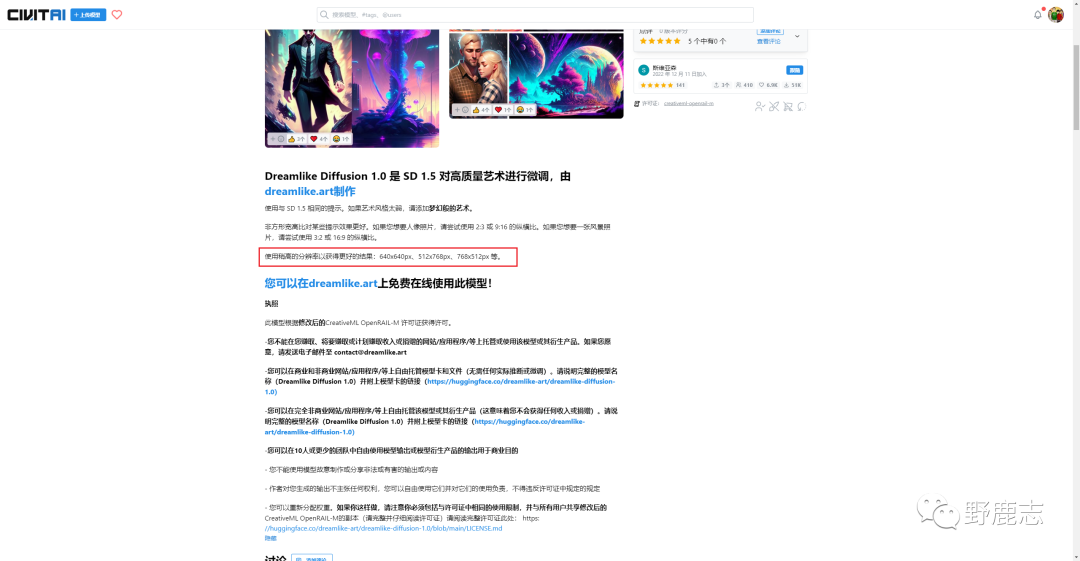
具体分辨率应该如何设置,我的个人建议是至少保证其中一个参数为512或者768,有一些模型它也会写明推荐的分辨率。
如果你确实想生成高分辨率图像,建议生成小的分辨率尺寸然后在此基础上开高清修复:
#06 生成批次和CFG
生成批次很好理解,相当于每次生多少组图,这些图的随机种子是依次增加的:
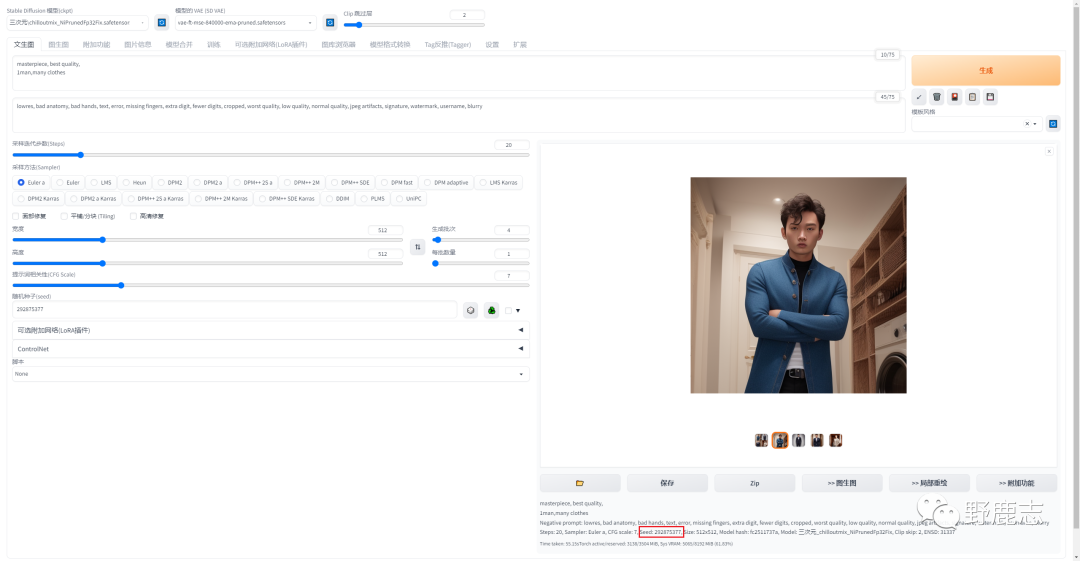
每批数量就是每组图有多少张,例如我这里生成了4批,每批数量是2,一共就是8张图:
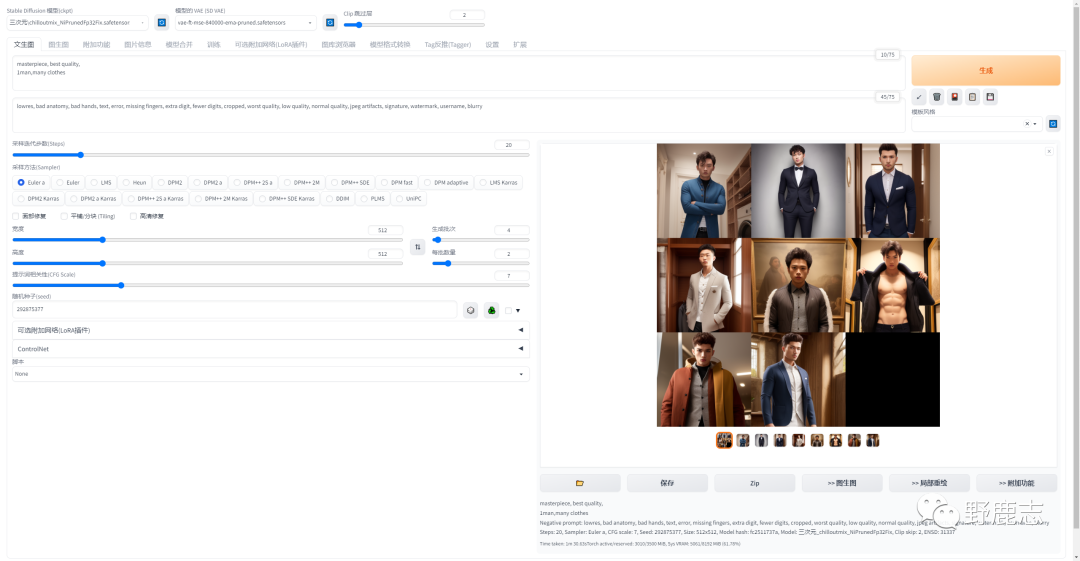
CFG参数控制生成图像的提词相关性,数值越高越接近提词内容,但过高会导致饱和度过曝,我这里同样以杰尼龟为例做了一个对比图大家可以看看:

#07 随机种子
最后一个参数随机种子,说到随机种子我们这里先提一下AI绘图的工作原理,用人话讲AI绘图就是先给一个噪声图,然后通过不断的调整往你的提词靠拢最后生成图片。
随机种子随机的就是这个噪声图,我这里用DDIM这种采样模式生成了一个采样迭代步数1到10的对比图:

可以看到当采样迭代步数为1的时候,就是一个噪声图,然后随着步数的增加逐渐形成一张图:

之前我们也提过,当你得到一个觉得不错的效果时候,可以点击环保图标按钮固定住随机种子。
这样在同样硬件环境以及参数不变的情况下,你每次得到的图可以达到百分之99的相似:
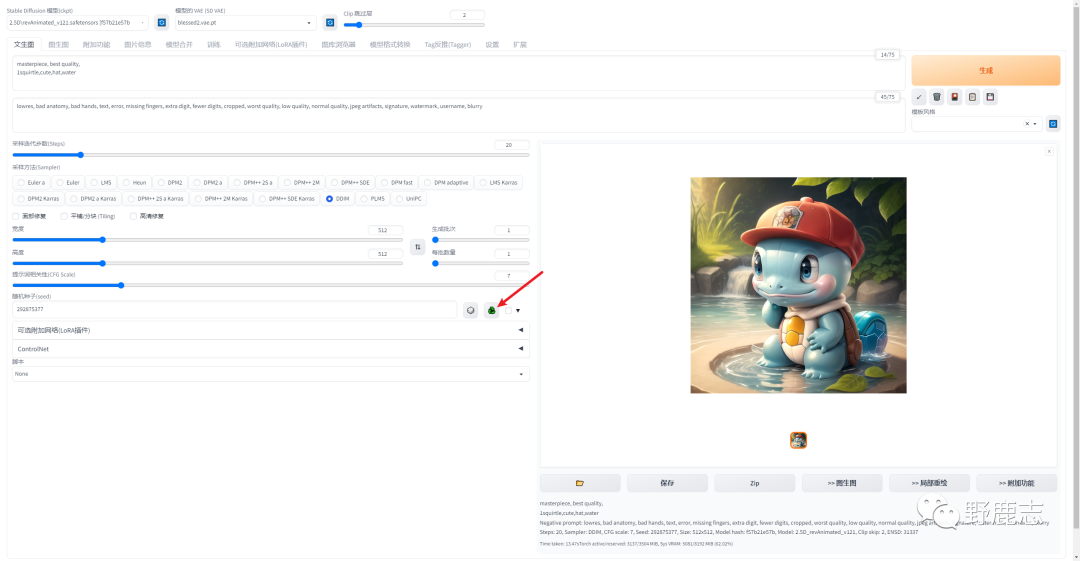
点击骰子按钮随机种子的数值会变成-1,这样每次都会使用一个新的随机种子:
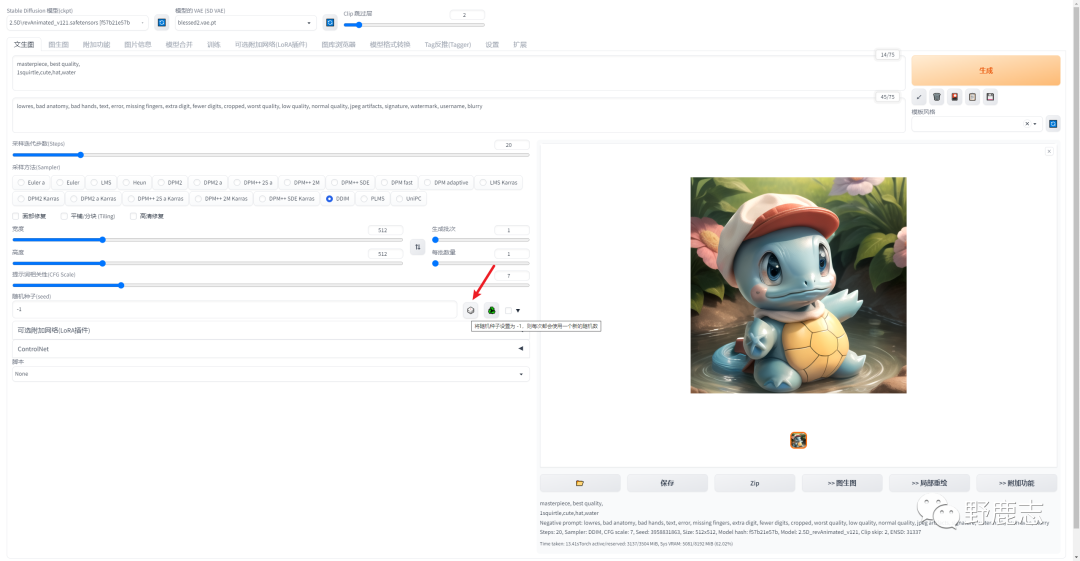
激活倒三角旁边的按钮之后,这里你还可以再设置一个随机种子,然后通过调整差异强度,将两个种子的图片进行混合。
下面的宽度和高度是指的生成图时按照你指定的分辨率的构图或者效果生成图片,但实际最终的分辨率还是你上面设置的出图分辨率,这个功能很少用:
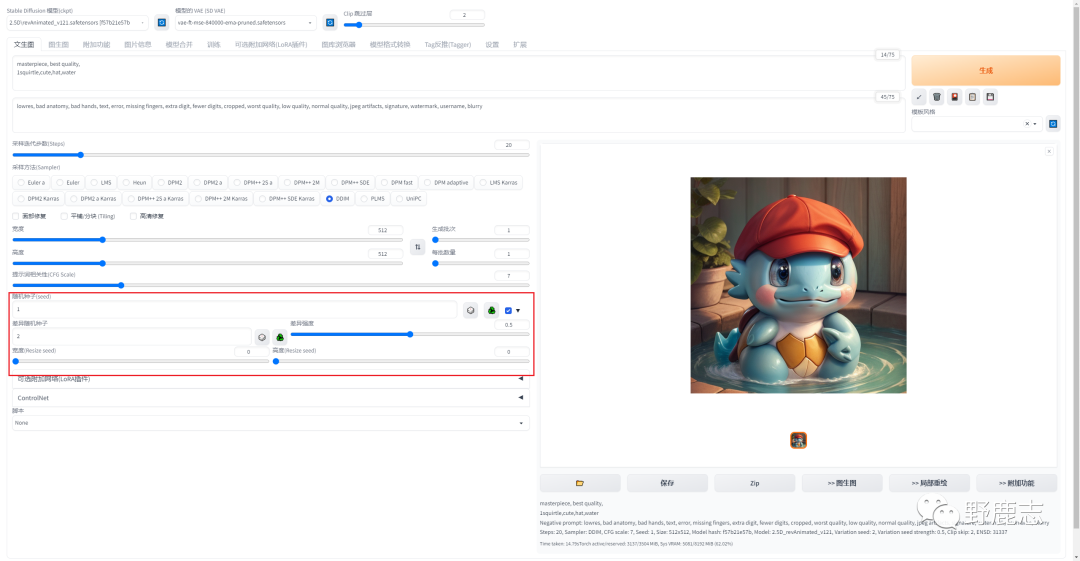
#08 Ai绘图小案例 杰尼龟
本来以上就是今天要分享的所有内容,但是由于我习惯了写案例的文章,所以就顺便把前面举例的杰尼龟案例弄完吧。
找到之前测试过程中还不错的一张图,上传到图片信息选项卡,它会自动读取到你的文生图参数信息,点击文生图:
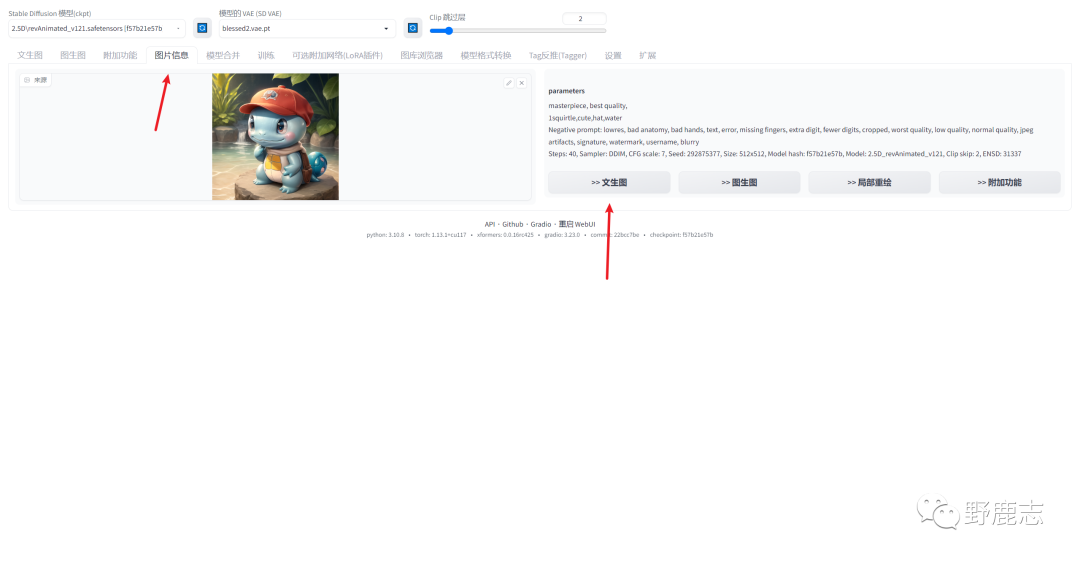
你的参数设置就会自动填写到文生图的各个栏位:

让我们在此基础上继续调整吧,首先我把模型切换为了ReV Animatedv1.2.2,这个是ReV Animated的最新版本,文末我也会把模型分享给大家。
然后尺寸我把高度改为了768,宽度保持为512,这张图之前用的采样方法是DDIM,我们不会,然后把采样迭代步数改为30生成图试一下:
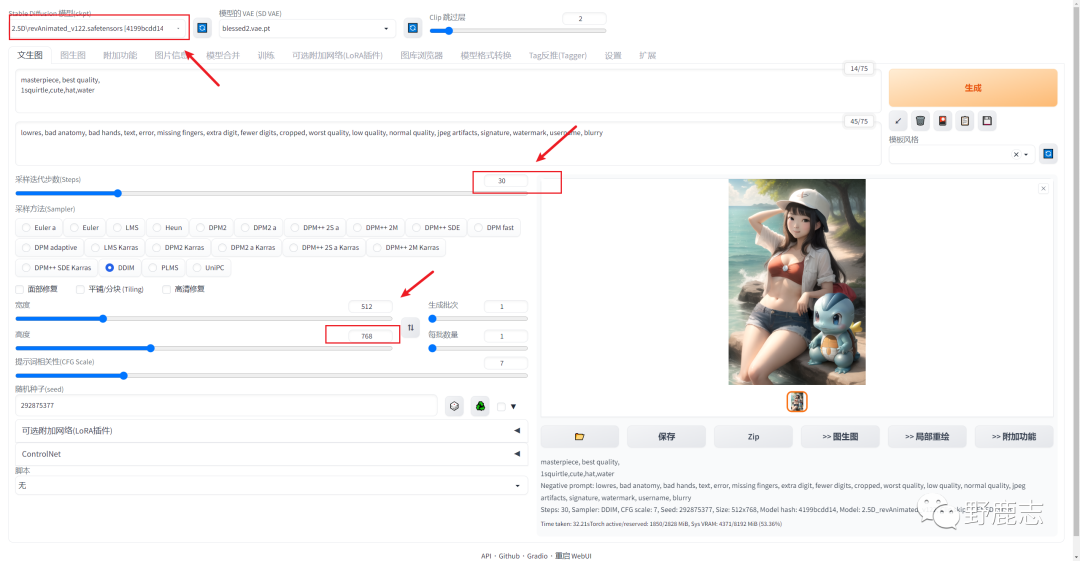
出问题了,生成的图片跑出一个女孩出来并且在翻车的边缘徘徊,我只希望出现杰尼龟。
所以在正向提词框内,我输入了“没有人类”,并且括弧加冒号1.3来提高它的权重。
同时为了避免翻车,反向提词里我输入了“NSFW(不适合在工作时间浏览的内容)”,权重为1.4:

接下来我们就需要找到一个比较合适的随机种子状态,固定住进一步微调。
大家可以通过生成多个批次的方式找到自己想要的状态,为了节约时间,我直接输入之前尝试好的seed:

C站上看一下这个模型的介绍,它是有推荐填写的正反向提词内容:
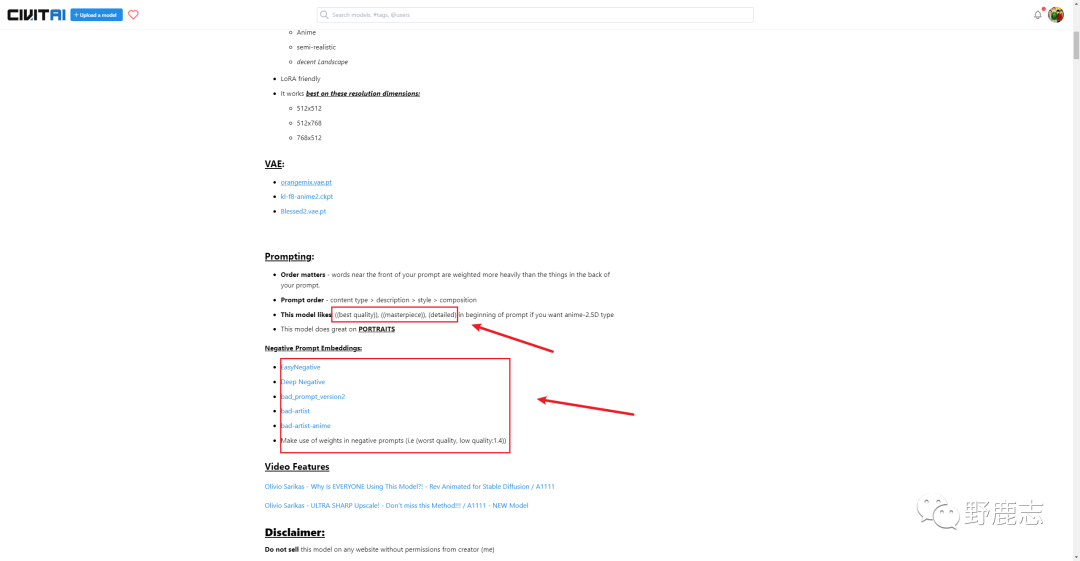
这些主要都是用于调整画面品质的提词,把它们都抄进提词框吧,模型介绍中的权重书写方式我改为了自己习惯的写法,这个以后我们再进一步分享:
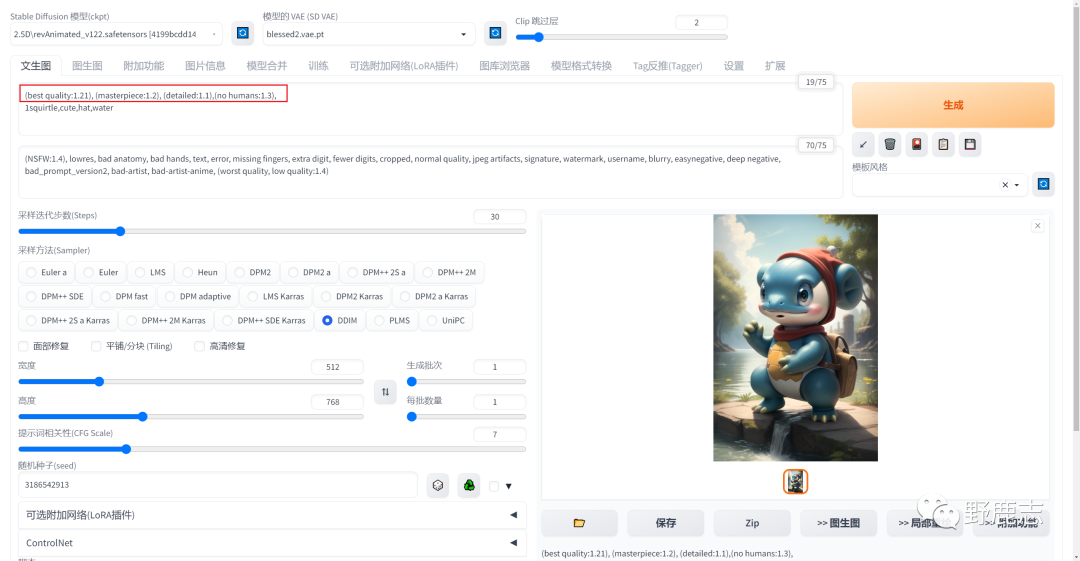
开始微调吧,提词内首先我把“一个杰尼龟,可爱,帽子,水”改成了“杰尼龟戴着绿色的帽子,可爱,水”:
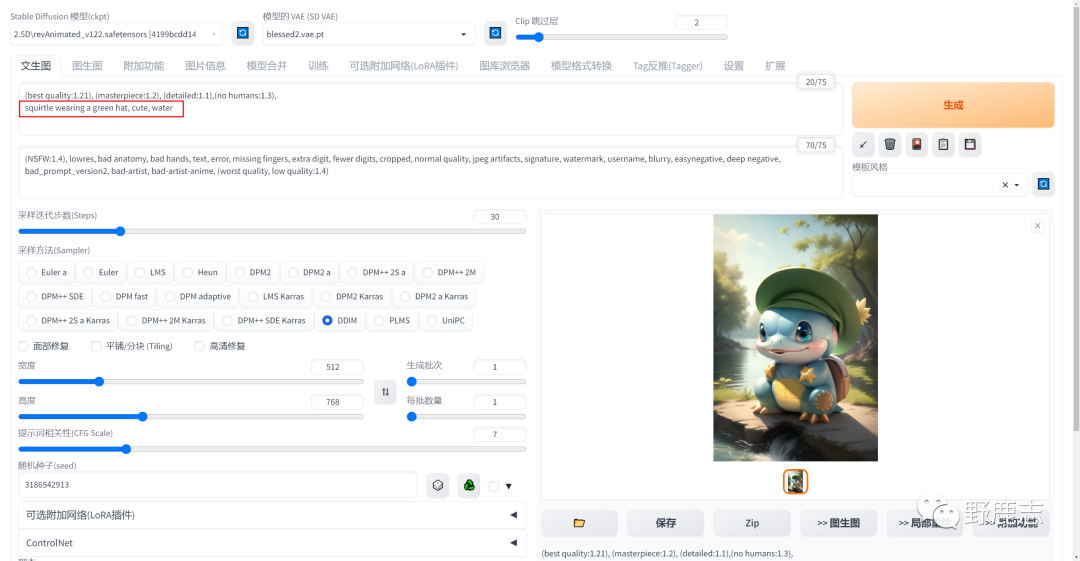
接着我在可爱后面输入了“chibi”,这个是用于描述Q版形象的意思,我记得杰尼龟的眼睛是红色的,所以又输入了“红色眼睛”:
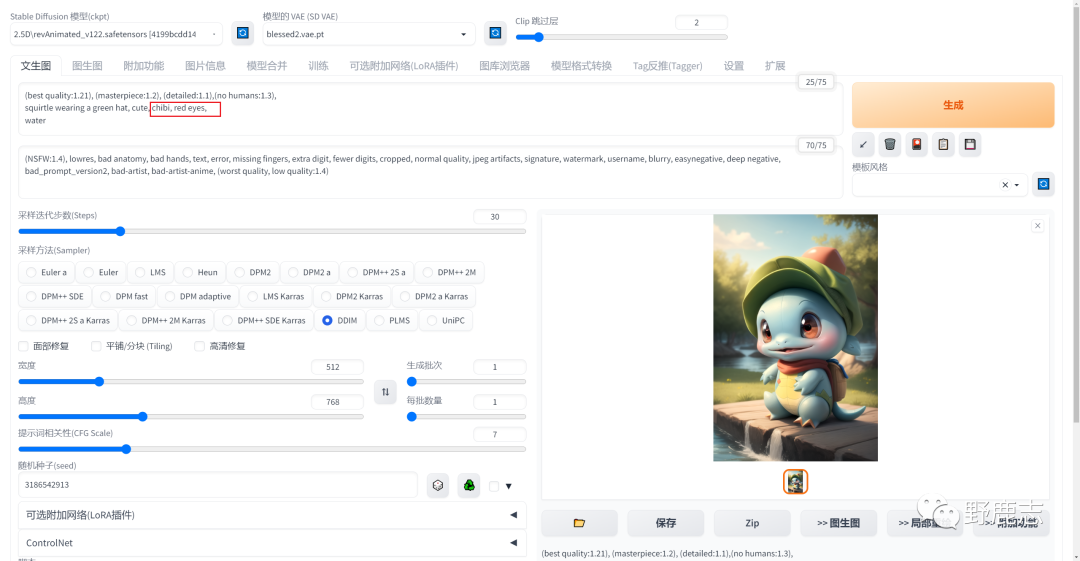
然后我又加入了“站立,张开短手臂,短腿,微笑”来进一步控制它的形态,大体感觉就出来了:
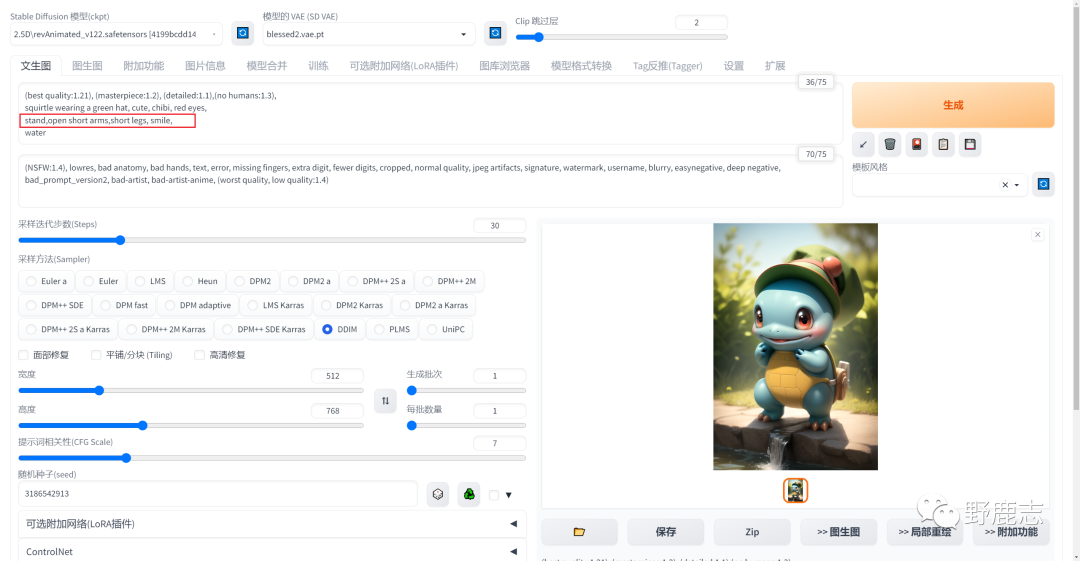
现在手部出现问题了,这个是最不好控制的,我这里首先把负向提词里和手有关的权重都提高了,但是现在又多出一个手出来:

所以负向提词里我加了一个“多余肢体”在最前面:
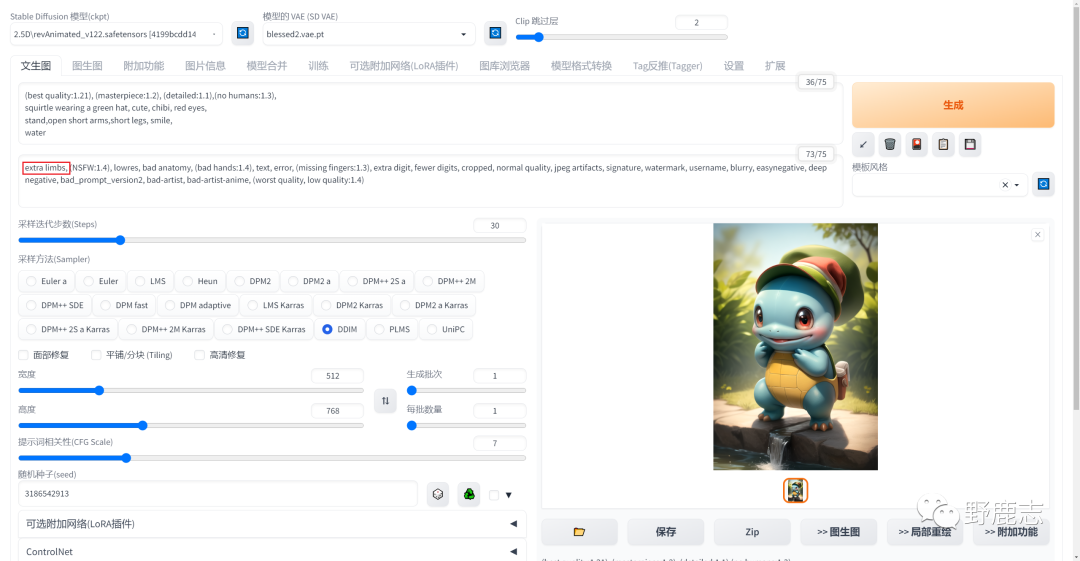
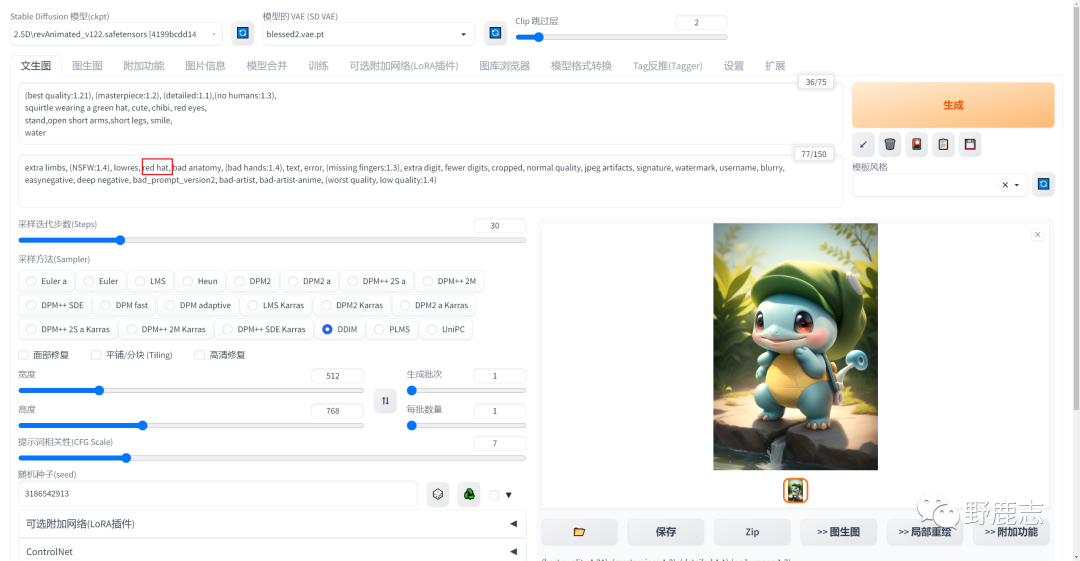
现在帽子出现了红色,我只想要纯绿色的帽子,所以在负向提词里加了“红色帽子”。
至于它的位置我建议大家先放到最前面开始尝试,如果对画面影响太大,就向后移。
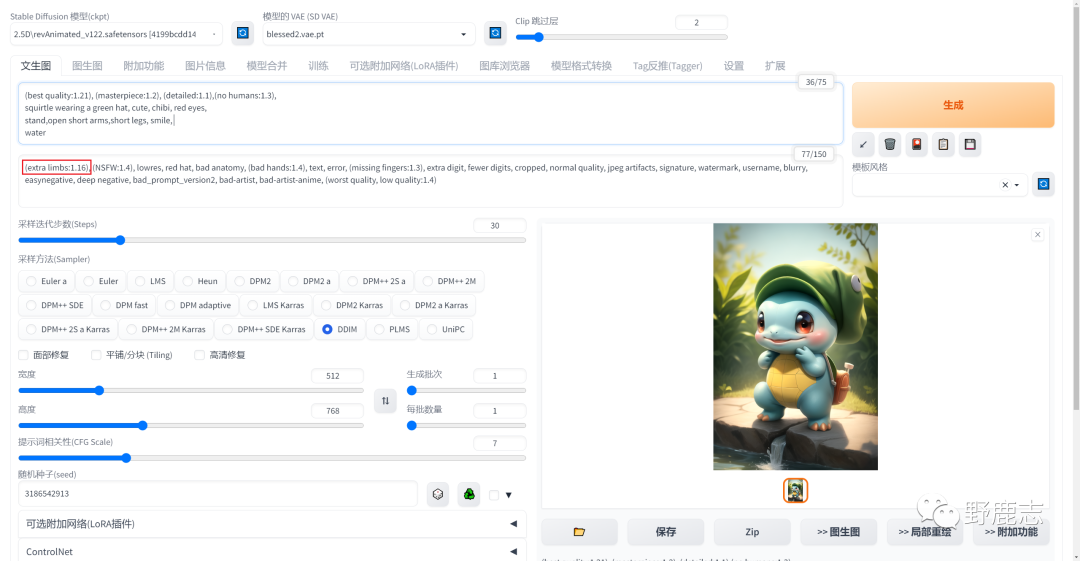
如图所示我移动到“低质量”后面的时候,画面影响不太大,但是又多了部分肢体出来:
所以再次提高“多余肢体”的权重,这个权重大家可以多尝试一下太高或者太低效果都不好:
另外有个知识点是我意外发现的,当我们在提词中连续输入两个逗号,即表示中间有个空白提词,对画面也有微弱的影响。
因为其实相当于还是改变了提词之间的前后顺序,也就是权重,例如这里意外的长出了尾巴这反而是我想要的:
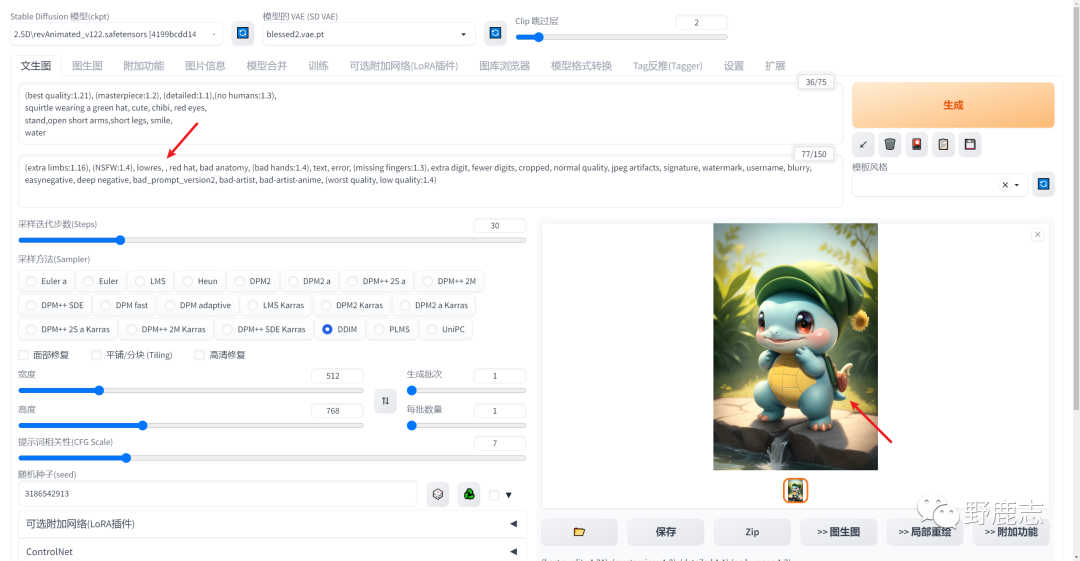
只是这种微调就需要多多尝试了,例如我这里尾巴虽然意外的长出来了,但是手指又多了,并且反而降低“多余肢体”的权重能得到满意的效果,有点玄学:

另外我开了高清修复,由于本身我对画面已经比较满意了,所以重绘幅度开得比较低,主要是为了放大分辨率,算法记得选择正确哦:
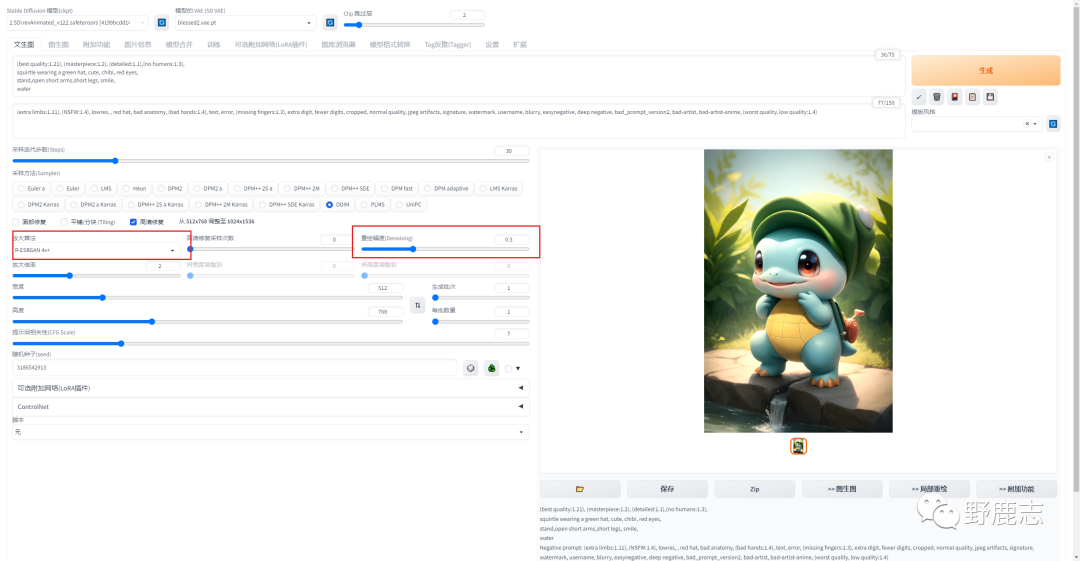
三、最终效果图
最后PS里调色排版看看效果吧:

以上就是今天要分享的所有内容啦,其实内容还是比较多的,希望对大家有所帮助,希望各位鹿友一键三连支持哦!
欢迎关注作者的微信公众号:「野鹿志」

学完这篇教程的人还在学…