昨天我们学习了如何文生图生成一幅图。今天我们将尝试用文生图生成一个全身像的女孩,并探讨在这个过程中可能遇到的问题和解决方法。
首先按照昨天的步骤,我选择“majicMIX realistic 麦橘写实”大模型,在提示词中我加入了“基础起手式”,并在正向提示词中简单加入了“一个女孩,全身像”。
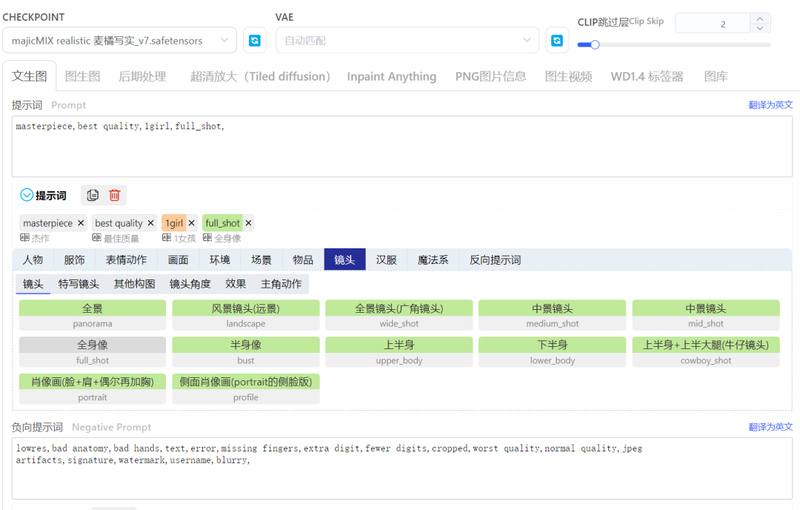
生成参数如下:
按照想象,应该生成一个全身的女孩图像,但是生成的结果是这样么?大家请看生成的结果。
抽了多次卡,仍然得不到想要的结果。

于是我把全身像权重调到了1.8,得到的图片仍然得不到想要的结果全身像。
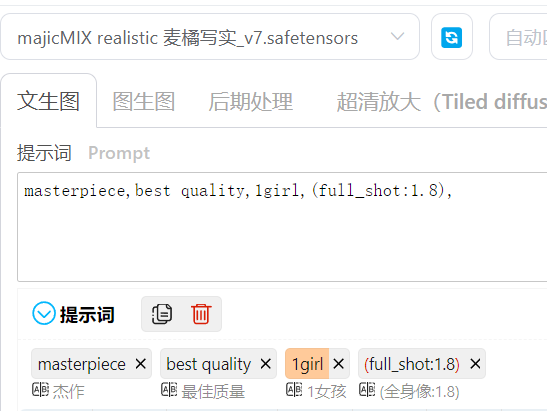

甚至我把全身像权重调到了2.3,得到的图片仍然不是全身像,而且图像有点崩图现象。

这是为什么呢?加大了全身像的提示词权重,仍然得不到全身像呢?
通过学习查看生成的全身像案例,发现别人生成的全身像,提示词用的是full body而不是full_shot。
于是我对提示词,进行了修改。修改后的提示词,改成了“masterpiece,best quality,1girl,full body,”,生成结果确实变成了全身像,(看来提示词还是很重要呀,也要多多学习他人的提示词是如何写的。)
但是每张图片都是脸部歪斜,这是为什么呢?


为什么?为什么?为什么呢?
这是因为AI会根据元素的面积大小分配像素,如果角色的面部很小,分配到的像素就会不足,从而导致变现甚至垮塌的现象。
那如何解决呢?
解决方法:
增加图片尺寸,将图片大小设置为512*680像素。再次生成图片,可以看到面部问题基本不会再出现问题了,但是像素密度有限,画面看起来不够精细。
紧接着,**问题又来了,**我们能否把图像设置成更大呢?比如:1024*1024呢?有一些图片变得更清晰了,但有些图片上会出现多个人物,甚至有些人物身上出现多余的肢体。

这是为什么呢?
因为SD1.5版本大模型使用的是512*512像素的图片训练的,生成的图片尺寸超过一定限制,AI以为图片是拼接的,因此就会出现多人和多余肢体的现象。
那如何解决呢?
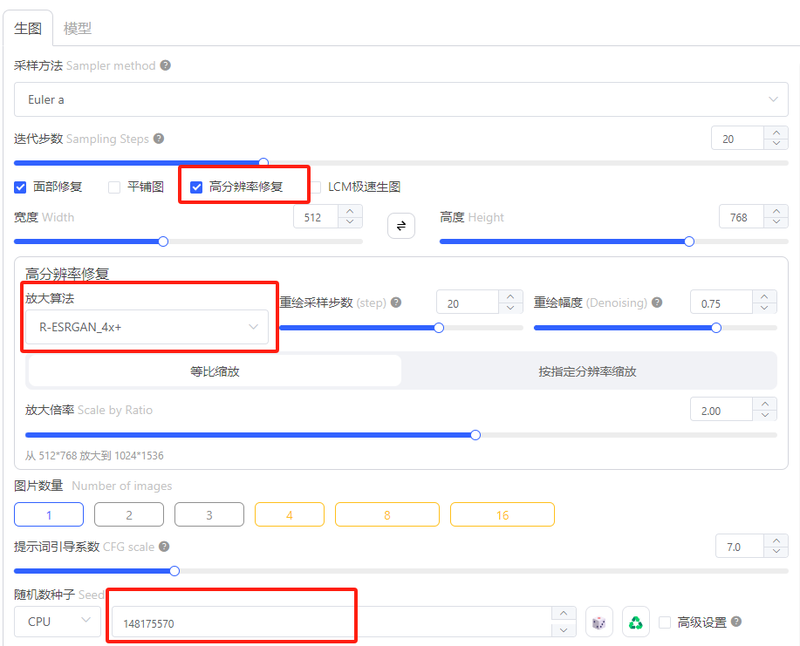
最有效的出图方式是把图像固定到合理像素内,增加总批次再生图,选中一张最理想的,用“高分辨率修复”。

结语
通过今天的教程,我们探索了在Stable Diffusion中生成全身像女孩的挑战,并学习了一些实用的技巧来克服这些问题。我们了解到,即使是微小的提示词变化,也可能对生成的结果产生重大影响。同时,我们也认识到了在图像生成过程中,参数调整和模型选择的重要性。
我们遇到了面部特征不准确和图像分辨率限制的问题,并通过调整图片尺寸、优化提示词和利用高分辨率修复插件找到了解决方案。这些经验教训不仅适用于当前的案例,也为您在未来的创作中提供了宝贵的参考。
请记住,Stable Diffusion是一个强大的工具,但掌握它需要时间和实践。不要害怕尝试不同的设置,进行实验,并从每次生成的结果中学习。随着经验的积累,您将能够更加自信地创作出符合预期的图像。
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、AIGC必备工具
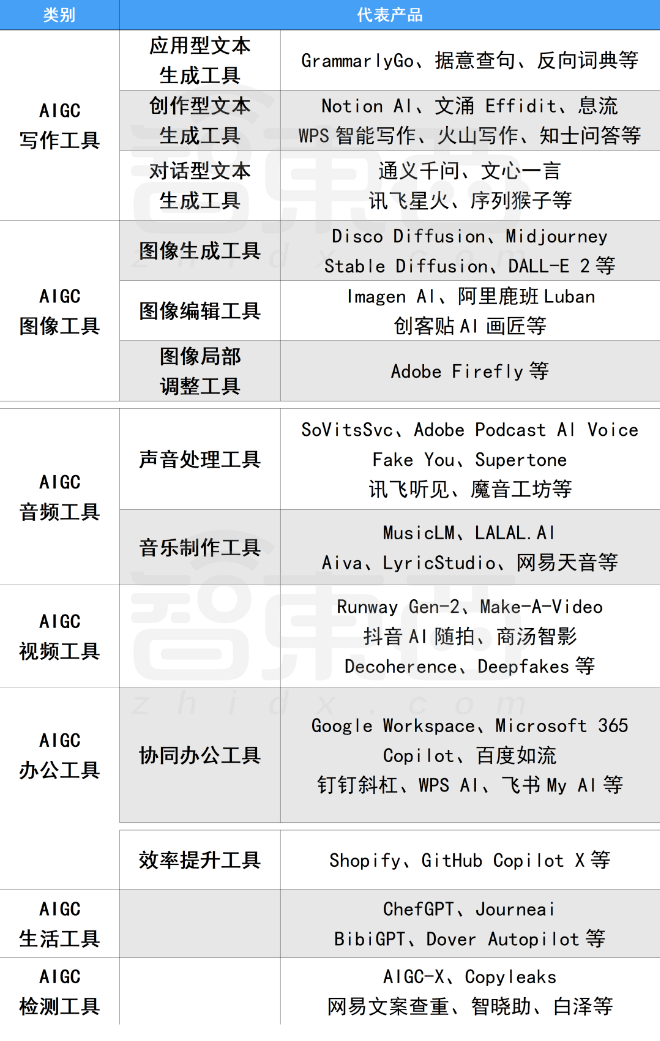
三、最新AIGC学习笔记

四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
若有侵权,请联系删除