大家好,又见面了,我是你们的朋友全栈君。
引言
去年Facebook开源了一套时序预测工具叫做Prophet。Prophet是一个预测时间序列数 据的模型。 它基于一个自加性模型,用来拟合年、周、季节以及假期等非线性趋势。 它在至少有一年历史数据的日常周期性数据,效果最好。 Prophet对缺失值,趋势的转变和大量的异常值是有极强的鲁棒性。Prophet中文翻译是:“先知”。名字还是挺贴切的。在看完本篇文章后,你将会知道:
- Prophet有什么亮点Prophet是怎么工作的如何去使用Prophet
为什么会发布这套工具
预测是一项数据科学任务,是组织内许多活动的核心。 例如,Facebook这样的大型组织必须参与容量规划,以有效分配稀缺资源和目标设置,以便衡量相对于基线的性能。 得到高质量的预测对于任何机器或大多数分析师来说都不是一个简单的问题。 在现实生活中,我做了不少商业预测,归纳总结发现,预测任务有两大核心问题:
- 完全自动化的预测技术往往都比较“脆弱”,不是太灵活,对一些问题缺乏有效的假设以及启发式的思路能够得到高质量预测的数据科学家是非常罕见的,因为预测需要丰富的经验以及专业的数据科学技能
在现实生活中,对高质量预测的需求往往要远远超过分析人员可以生产的速度。因此Prophet的出现就是为了让专家和非专家能够更轻松地进行高质量的预测。
很多人在做预测的时候,总会提出这个一个潜在的考虑因素:“规模”。当我数据量很大的时候,计算与存储的开销能满足要求么?其实对于时序预测问题,计算问题可以通过并行执行解决,存储问题可以通过关系型数据库MySQL或数据仓库Hive解决。 Prophet解决的“规模”问题,其实本质上是在完成时序预测任务时面临的各种复杂情况,Prophet能够适用于多种业务场景下的预测。
Prophet的亮点
当你做了很多时序预测任务时,你就会发现,并不是所有的任务都能用一个预测流程来解决。“一招鲜,吃遍天”在数据科学里是行不通的。通过分析平时我们做时序任务时遇到的问题,我们发现给定的时序数据有以下几个特点:
- 观察值是按每小时或每天或每周或每月给出的一段历史数据多尺度的周期性:一周七天,一个月30天,12个月等等提前已知的一些重要假期:各种法定节日或传统节日数据中存在缺失值或异常值历史趋势的变化趋势是非线性变化,达到自然极限或趋于饱和
Prophet通过将全自动预测与在线学习相结合从而保证了该工具能够解决大多数商业业务问题,Prophet工作流程如下图所示:
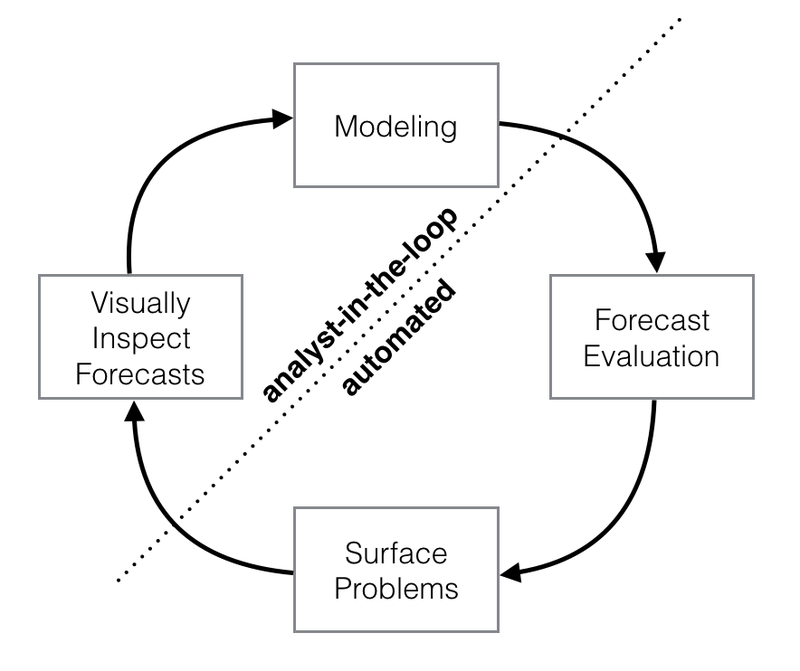
相比于目前开源的一些预测工具,Prophet主要有以下两点优势:
- Prophet能够让你更方便直接地创建一个预测任务,而其他的一些工具包(ARMA,指数平滑)等,这些工具每个有自己的优缺点及参数,即使是优秀的数据分析师想要从众多的模型中选择合适的模型及相应的参数也是够让他头皮发麻的。Prophet是为非专家们”量身定制”的。为什么这么说呢?你利用Prophet可以直接通过修改季节参数来拟合季节性,修改趋势参数来拟合趋势信息,指定假期来拟合假期信息等等。
Prophet是如何工作的
本质上讲,Prophet是由四个组件组成的自加性回归模型:
- 分段线性或逻辑增长曲线趋势。 Prophet通过从数据中选择改变点,自动检测趋势的变化。用傅里叶级数模拟每年的季节性分量。用虚拟变量来模拟每周的周期性分量。用户提供的重要节日列表
Prophet其中最重要的思想就是曲线拟合,这与传统的时序预测算法有很大的不同。
如何使用Prophet
安装
因为Prophet已经发布在PyPI上了,所以我们可以通过pip进行安装:
$ pip install fbprophet我的是ubuntu16.10版本,软件大小为68.1MB
快速启动
Prophet遵循sklearn模型API。 我们创建一个prophet类的实例,然后调用它的fit和predict方法。 Prophet的输入必须包含两列数据:ds和y,其中ds是时间戳列,必须是时间信息;y列必须是数值,代表我们需要预测的信息。首先我们获取数据:这里我们采用官网给出的Peyton Manning这个维基百科页面日常被访问的数据(下载链接)。
然后我们导入相关库以及数据:
# Python
import pandas as pd
import numpy as np
from fbprophet import Prophetdf = pd.read_csv('example_wp_peyton_manning.csv')
df['y'] = np.log(df['y'])
df.head()dsy02007-12-109.59076112007-12-118.51959022007-12-128.18367732007-12-138.07246742007-12-147.893572
m = Prophet()
m.fit(df);# Python
future = m.make_future_dataframe(periods=365)
future.tail()ds32652017-01-1532662017-01-1632672017-01-1732682017-01-1832692017-01-19
# Python
forecast = m.predict(future)
forecast.tail()dstrendtrend_lowertrend_upperyhat_loweryhat_upperseasonalseasonal_lowerseasonal_upperseasonalitiesseasonalities_lowerseasonalities_upperweeklyweekly_lowerweekly_upperyearlyyearly_loweryearly_upperyhat32652017-01-157.1890856.8364607.5568977.5290098.8742591.0176681.0176681.0176681.0176681.0176681.0176680.0482860.0482860.0482860.9693820.9693820.9693828.20675332662017-01-167.1880596.8344737.5573507.7839239.2376961.3437071.3437071.3437071.3437071.3437071.3437070.3522980.3522980.3522980.9914090.9914090.9914098.53176632672017-01-177.1870336.8324127.5578027.5556369.0612721.1321231.1321231.1321231.1321231.1321231.1321230.1196310.1196310.1196311.0124931.0124931.0124938.31915632682017-01-187.1860066.8300797.5582557.4563708.9823070.9657650.9657650.9657650.9657650.9657650.965765-0.066664-0.066664-0.0666641.0324291.0324291.0324298.15177232692017-01-197.1849806.8277577.5584747.4455088.8897370.9787100.9787100.9787100.9787100.9787100.978710-0.072264-0.072264-0.0722641.0509731.0509731.0509738.163690
m.plot(forecast)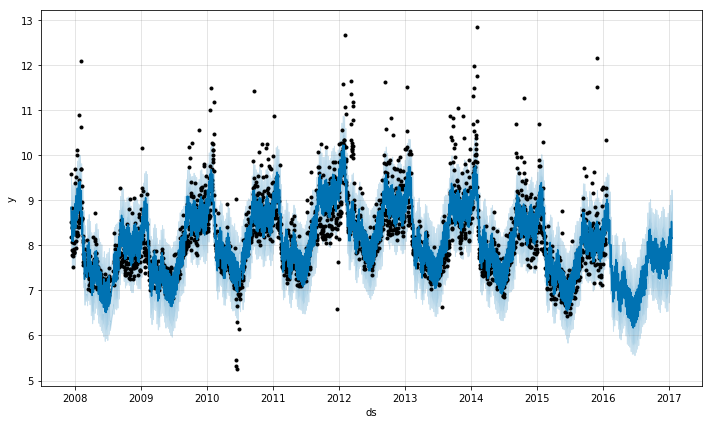
m.plot_components(forecast)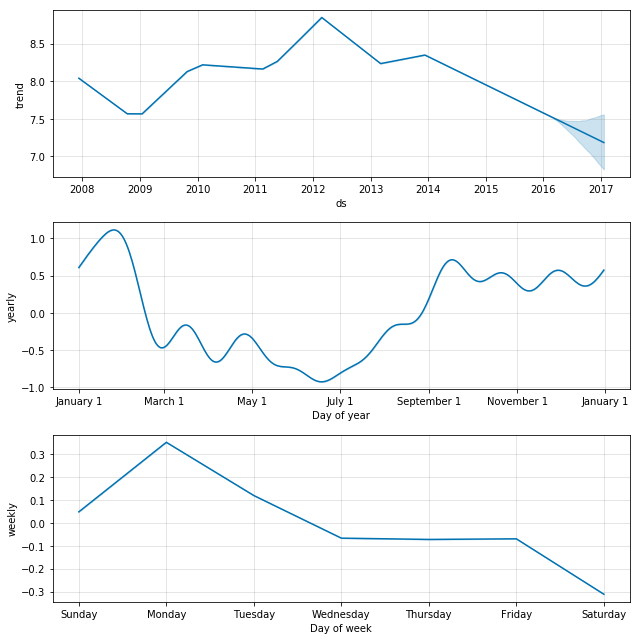
不同业务场景下的预测效果
这一小节,我们基于不同业务场景,看看Prophet的预测效果好不好。
饱和性预测
这里通过制定预测值的上限、下限,从而来进行饱和性预测
#Forecasting Growth
df = pd.read_csv('example_wp_R.csv')
df['y'] = np.log(df['y'])df.head()dsy02008-01-305.97635112008-01-166.04973322008-01-176.01126732008-01-145.95324342008-01-155.910797
# 指定上限df['cap'] = 8.5
df['cap'] = 8.5
m = Prophet(growth='logistic')
m.fit(df)
future = m.make_future_dataframe(periods=1826)
future['cap'] = 8.5
fcst = m.predict(future)
m.plot(fcst)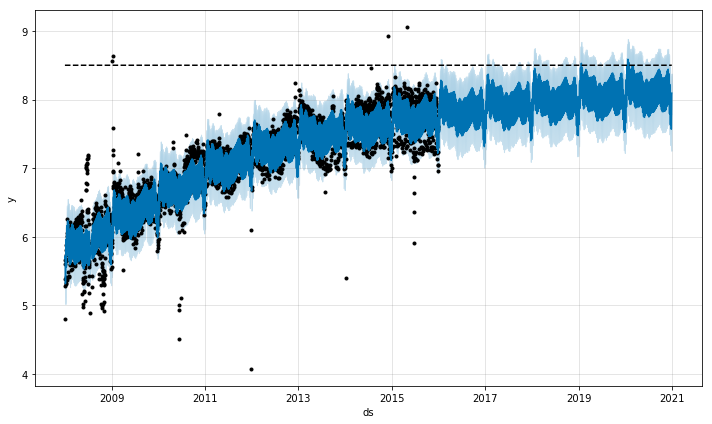
趋势变化点
Prophet能够实现历史趋势变化点的自动检测,并可以通过调整参数适当修正变化。Prophet通过changepoint_prior_scale来调整变化点的趋势程度,值越大,趋势就越灵活。同时Prophet通过参数changepoints来手动指定趋势变化点。
m = Prophet(changepoint_prior_scale=0.5)
forecast = m.fit(df).predict(future)
m.plot(forecast)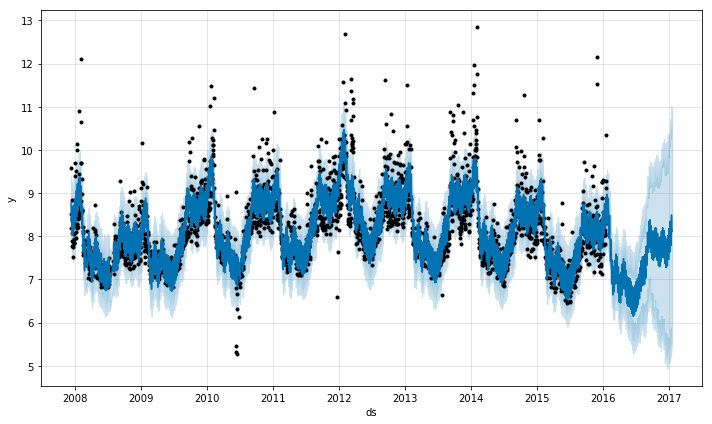
m = Prophet(changepoint_prior_scale=0.001)
forecast = m.fit(df).predict(future)
m.plot(forecast)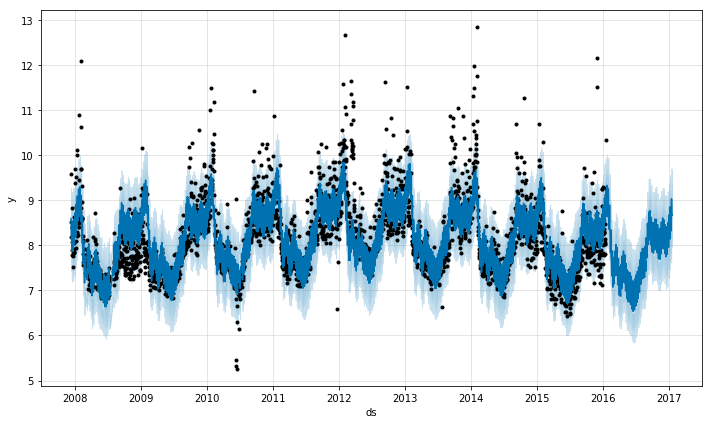
m = Prophet(changepoints=['2014-01-01'])
forecast = m.fit(df).predict(future)
m.plot(forecast)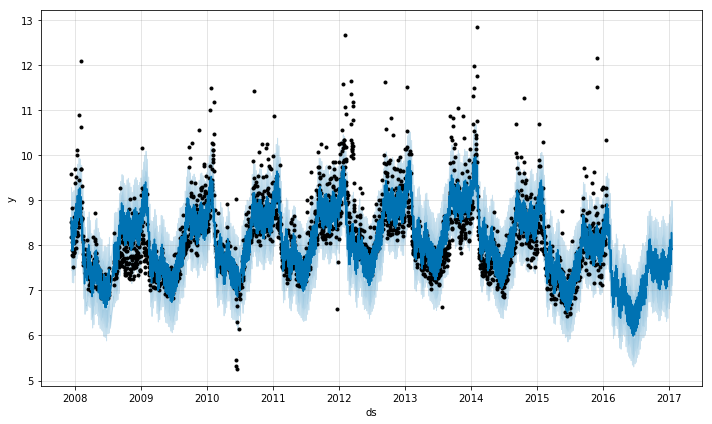
Prophet在异常值、缺失值、周期性、季节性、节假日等方面效果也不错,这里就不赘述了。
总结
读了这篇文章,是不是感觉这个Prophet很好用,是不是迫不及待想去试试水?哈哈哈 demo代码:github : Prophe_in_action
发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/147679.html原文链接:https://javaforall.cn