哇塞,绘画0基础就能做出这样的图吗? AI的绘图技术已经如此强大了吗?初次见到别人使用AI绘图的成果时,再和我的AI出的图一比较,我感到非常震撼和惊讶。然而,当更让我忍不住想要迫切了解的是,它是如何实现这种效果的。
在开始这篇文章之前,我想先给大家介绍一下我个人学习深入SD的学习曲线。
1. 先学最基础的,大概理解参数模型提示词的用途,先把sd的流程跑通,这一步大概可以做出来相对看得过去的图了
2. 然后再去研究模型和提示词的高级用法,比如,混用lora模型,提示词的分步和融合写法,这个时候,必然会涉及到一些原理性的东西,就会理解为什么AI画不好手了。到这一步,可以对图进行针对性的优化了,比如说一个图怎么达不到提示词想要的效果,可以针对性地优化提示词。
3. 学习其他功能,图生图,control net插件,以及分层控制Lora模型等进阶功能。
4. 训练自己的模型
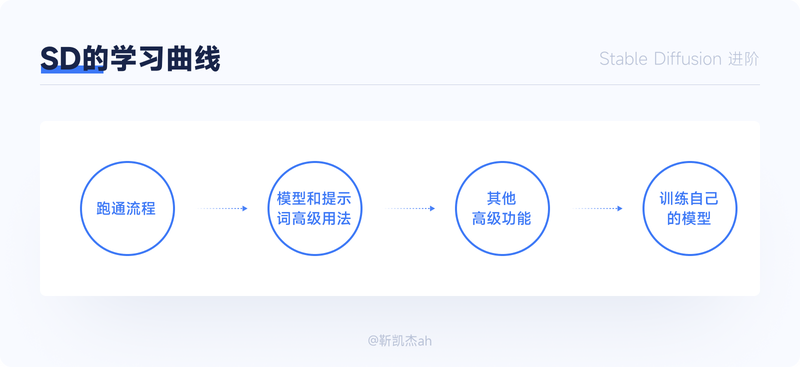
上一篇文章集中在第一步,这篇文章会讲解一下第二部分和第三部分。没有看上一篇的基础篇的建议先看完上一篇再食用。上一篇文章指路:https://www.zcool.com.cn/article/ZMTUzODI2NA==.html


XYZ图表的使用
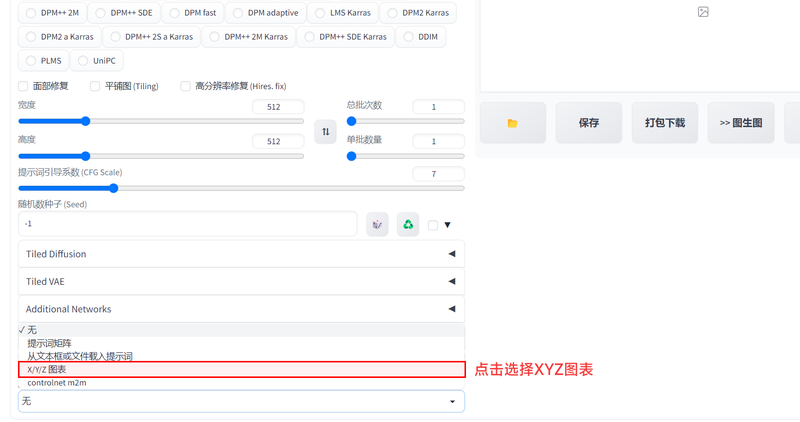
XYZ 三维图表是一种用于可视化三维数据的图表。它由三个坐标轴组成,分别代表三个变量。这个工具的作用就是可以同时查看至多三个变量对于结果的影响。具体在sd中,xyz图表可以帮助我们观察到三个变量的变化对图像的影响,以便我们更好的调整参数,如此,我们便对各个参数的作用更加了解,即使以后sd更新了新参数,我们也可以在不需要教程的情况下知道该参数的含义。这项功能可以在 文生图/图生图 界面的左下角中 “脚本” 一栏内选择 “X/Y/Z 图表” 以启用。
举个例子,我们想要测试采样器(Sampler),迭代步数(Steps)和基础底模型(Checkpoint name)三个变量对图片的影响,点开X类型,选择为采样器,Y和Z依次设置为迭代步数和基础底模型。
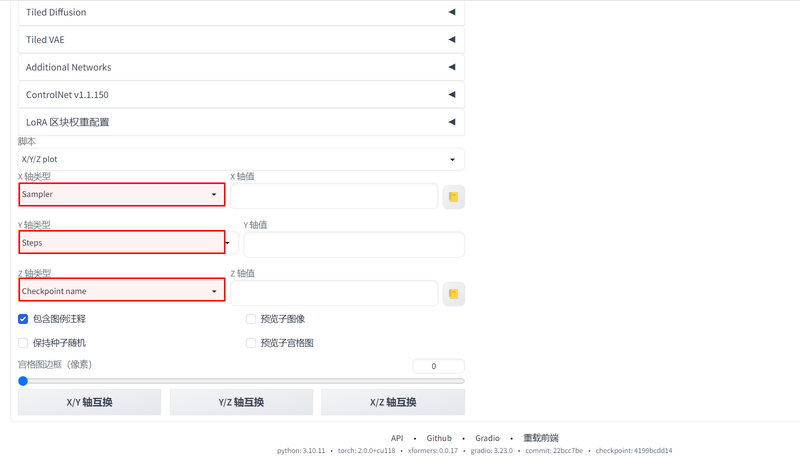
在填各个轴数值的时候,将对应的参数以英文逗号隔开即可。以X轴的sampler为例,我们可以把要对比的采样器的名称复制进去。另外,也可以点击右边的“book”图标,加载本地所有的采样器,然后删除掉不需要的即可。在填Y轴的迭代步数时,除了可以直接输入数值外,也可以采用另外两种方式来写。
1. 起点-终点(间距),例如:20-50(+10)就表示,从20到50,每一步加10。
2. 起点-终点[步数],例如20-50[4]就表示,从20到50,一共四步。
这两种方式的效果都与直接输入“20,30,40,50”等效。最终我们会得到一个这样的网格图。

这里还有一个小技巧,如果我们觉得图与图之间没有间隔,混在一起不好区分,可以调整这里的数值,来增加图与图的间隔。将这里的间隔调整为12后效果如下:

提示词矩阵
基本使用方式
在许多情况下,一大串从网络上抓取的提示词在某些模型中表现良好,但在更换模型后可能就无法使用。有时候,一些看似无用的提示词被移除后,画面的感觉会变得怪异,不清楚到底是哪里受到了影响。这时候,就可以使用Prompt matrix来深入探究原因。与之前介绍的X/Y/Z plot相比,Prompt matrix的使用方式相似,都可以生成一组图表,但它们的设置方式有很大的差别。我们举个例子来说明这个脚本的使用方法:例如我们在别人的提示词中看到了这两个词:dutch angle,autumn lights,翻译过来是倾斜的角度,秋天光影,每个字都懂,但是我们还是无法知道这些词对图像的影响。
1. 首先我们把选择提示词这个部分选中正面。(默认就是选中正面,不需要去更改)。其他参数我们保持默认即可。
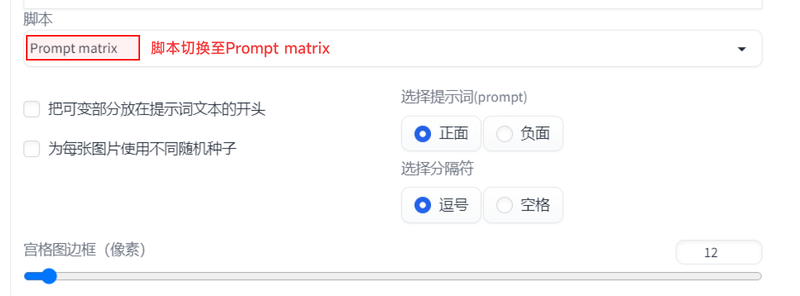
2. 接下来我们将两个词填入正向提示词中,这里的格式是“|测试提示词1|测试提示词2”。

在上面的这个图中,第一行的提示词会被用在每一张图上,第二、三行被“|”分割的提示词,会被当成矩阵提示词,交错添加在最终的图上。
3. 然后,我们可以产出这么一张图。

左上角的第一张图,就是什么额外提示词都没加的状态,它第二列的图,则全都是添加了“dutch angle(倾斜角度)”这个提示词的效果。第二行则是都增加了“autumn lights(秋天光影)”提示词的效果。而最右下的,就是倾斜角度与秋天光影全部提示词都有的效果。 这样你就能很清楚地看到,各种提示词交互叠加起来的效果。
进阶使用
提示词矩阵不止一次可以对单个词进行测试,还可以将一组词组合在一起进行测试。例如:

以此作为提示词产出的图如下:


在完成最终的绘图后,有时我们可能会发现一些小问题,或者想要微调画面。这时,我们可以使用“变异随机种子”来实现。以这样一张原图为例:

首先,我们先将随机种子确定,然后将这里勾选后,下面的子参数“变异随机种子”会被打开,变异幅度越大,最终的图与之前的图的区别越大。一般来说,我们会把这个值调整为0.3,当然,这里也可以借助上面介绍过的xyz图表进行尝试,找到一个最合适的值。另外,我们可以把批次数提高,找到最合适的结果。
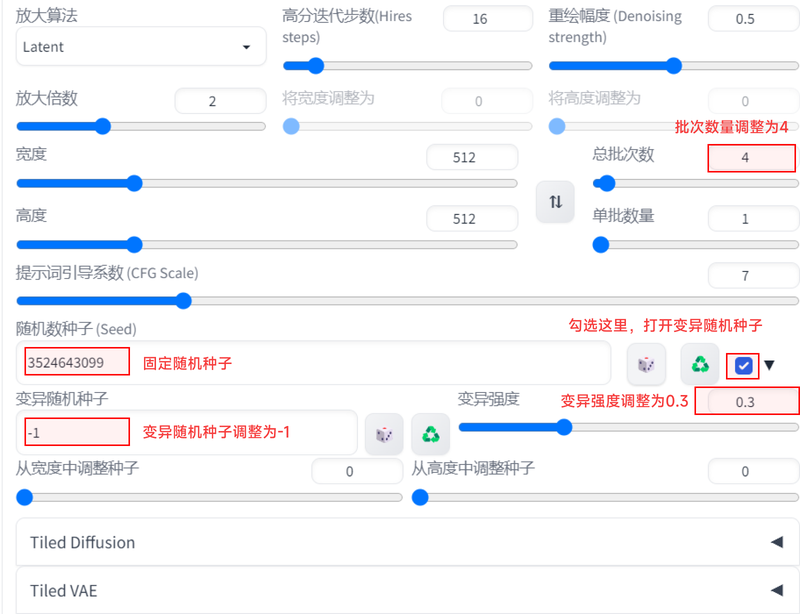
最终,我们可以得到这样的结果。


由于显存大小的限制,通常我们只能在出图时生成512*512大小的图像。然而,这个大小的图像通常不够清晰,即使进行高清修复,也只能将分辨率提高到1024*1024。如果我们强行将分辨率改变为2000以上,要么显存直接爆掉,无法生成图像,要么生成的图像会出现各种奇怪的问题。为了解决这个问题,我们可以使用“multi diffusion”插件来放大图像。这是目前图像放大的最佳解决方案,可以在放大图像的同时补充细节。
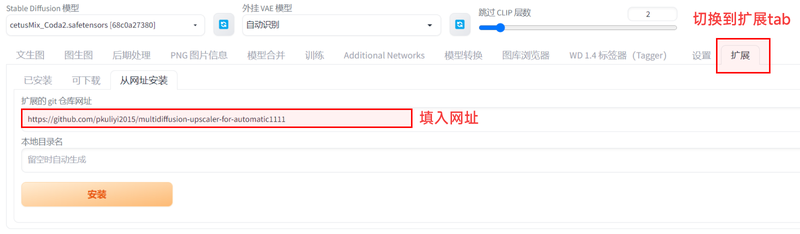
插件的安装
一般来说,在秋叶的整合包中已经自带了这个插件。如果没有的话,点击扩展→从网址安装→重启ui即可。网址如下:https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
插件的使用
使用前的准备
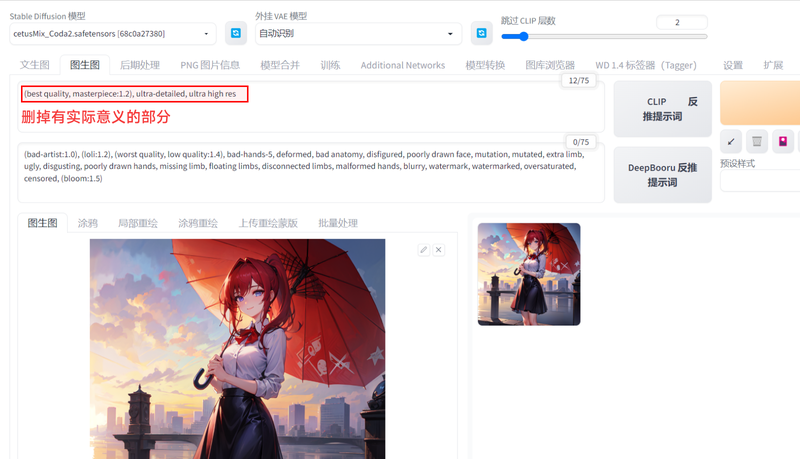
1. 去掉正向提示词中的有实际意义的部分,只留下例如"highres, masterpiece, best quality, ultra-detailed 8k wallpaper, extremely clear"的词汇。由于这个插件的原理是对大图进行分块绘制,如果在正向提示词中加入了具体对象,会使得这个对象遍布在图像的各个区域。
2.【可选】把提示词引导系数调大,例如调到15左右,经过我的测试,效果是要好于7的,但是差别不大。
插件参数设置
我们首先将要生成的图发送到图生图下,将页面往下滚动,找到这两个标题,并点击右侧的箭头展开设置项。
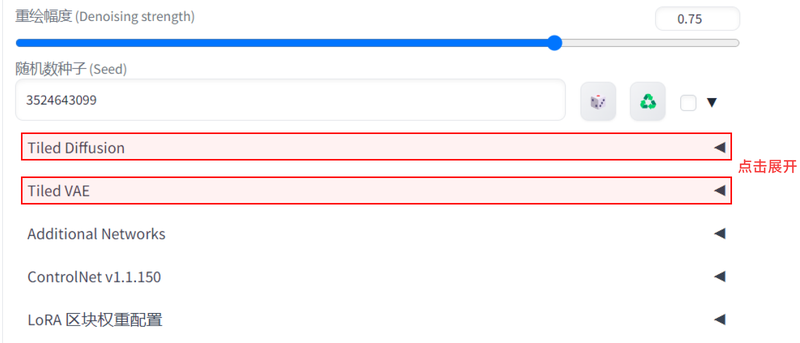
Tile Diffusion 参数设置
我们只需要调整以下五个参数即可,其他参数保持默认即可。放大算法:真人图像用4x+,二次元图像用4x+anime。
放大倍数,即最终图像相对于原图的放大倍率。
renoise stength推荐“0.3-0.6”之间。
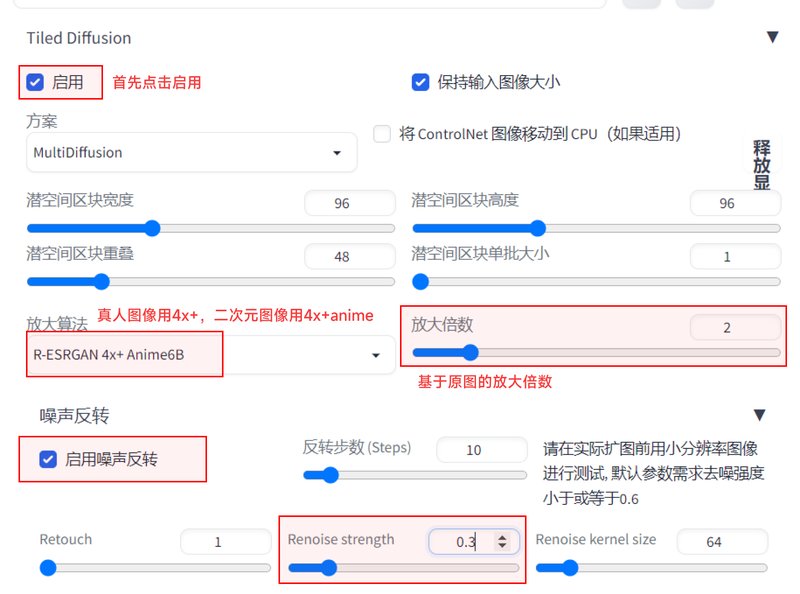
Tiled VAE
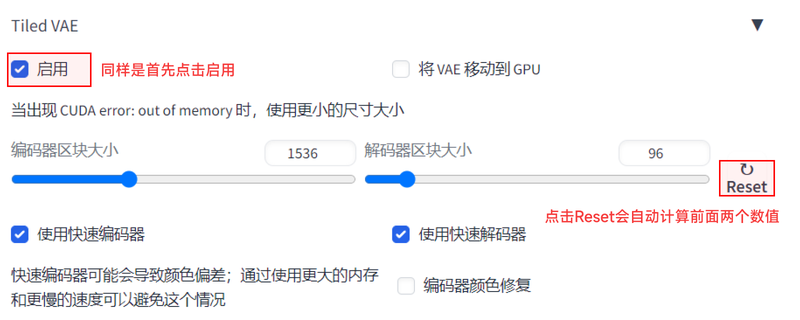
首次使用时点击reset,系统会自动计算出最适合当前电脑配置的编码器区块大小和解码器区块大小。然后如果放大后的图颜色失真,勾选压缩编码器颜色修复即可。最后,我们点击生成即可。从右下角的图片信息可以看到,我们已经得到了2k的图。
并且在原比例显示时,也是非常清晰的。

在之前的文章中,我们介绍了提示词的基本语法和撰写方式,在这里我们要介绍一下更进阶的语法和使用方式。
提示词的顺序
先说结论:越重要的提示词应该放到越靠前的位置。这里做一个测试,1girl,1cat

可以看到,当cat这个提示词在前时,猫的细节明显多了很多,而且甚至AI将猫耳的元素加到了人物身上。结论:Prompt的顺序会影响画面的组织方式,越靠前的Prompt对构图的影响越大。虽然本次试验只涉及一个场景,但在更多的后续探究和复杂场景构建中,这种影响的有效性已经得到证明。然而,它并非绝对有效,在某些情况下或者较为复杂的场景中,这种规律可能会失效,但总的来说,遵循这个规律写提示词更容易获得自己想要的场景。
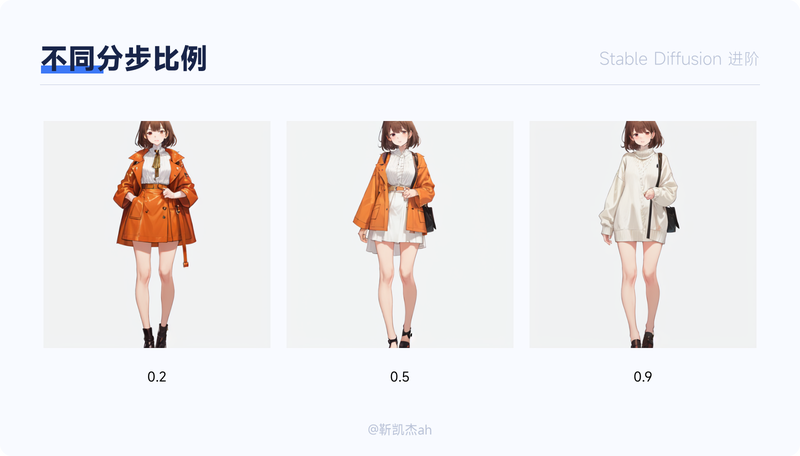
分步描绘
有时候,在特定的情况下,你可能希望一个提示词在计算过程中持续到达到X%时停止,或者在达到X%时才加入,或者在开始时使用提示词A,然后在达到X%时切换到提示词B。在这种情况下,SD提供了这样子功能的语法:[A:B:number] 表示:A提示词跑到number之后换成B提示词[A:number] 表示:A提示词跑到number之后才开始加入 [A::number] 表示:A提示词跑到number的时候停止使用我们来看一个例子:假设你想画一位穿着白色毛衣和橘色皮衣的女孩,并测试不同比例的Prompt的效果,你可以尝试以下方式:[White sweater:orange Leather coat:0.2]这意味着前20%的图像使用“白色毛衣”提示词进行绘制,剩下的80%则使用“橘色皮衣外套”提示词继续绘制。同样,[White sweater:orange Leather coat:0.5]表示在绘制到一半时,提示词从“白色毛衣”转换为“橘色皮衣外套”,而 [White sweater:orange Leather coat:0.9] 则表示在绘制到90%时才切换到“橘色皮衣外套”。以下是效果对比:
融合描绘
语法是:[提示词A|提示词B]。这种用法非常罕见,基本上就是在每个回合中不断轮流使用提示词,效果会变得难以预测。例如,下图使用了这样的提示词,[black hat|red hat]是黑帽和红帽提示词交替使用,但实际上生成的帽子并没有真正变成红黑相间,而是黑底帽子带有了红色装饰。

笔者建议,这种用法慎用,可控程度相当低,很容易出现奇奇怪怪的图。
反向提示词的进阶用法
反向提示词的高级用法不仅仅是写一些低质量的提示词,还可以写一些与正向提示词相关但不需要的提示词。例如,在正向提示词中,上半身通常会默认绘制手,但是我们可以将手写入反向提示词中,从而达到更加自由的绘制效果。
借助ChatGPT写提示词
在编写提示词时,我们可能会遇到不知道如何描述一个场景的情况。例如,我们想要绘制一张女孩在咖啡馆里看书的画面,但不知道如何描述这个场景。这时,我们可以借助ChatGPT来提供灵感,打开思路。具体操作如下:首先给ChatGPT一个基本的提示,让它帮助我们产生画面描述。我这里的基本提示如下:假设你现在是一个创意插画师,接下来我会给你一些提示,你需要以这个提示为依据,去组合想象生成一副插画的语言描述,请注意,不允许用长句,尽可能用词汇,其次是短语。另外尽可能多地合理地去补充场景中对人或风景的细节和特征,不少于5处,例如主体的衣着,长相,姿势,背景的花草树木等,尽可能的帮我补充这些我没有提到的细节,整体内容丰富一点。大家可以直接复制,也可以在此基础上加入一些其他细节。之后,我们输入一个简单的场景描述,例如“女孩坐在咖啡馆”,ChatGPT就会给出对应的画面描述,接下来,我们从中提取出重要的提示词即可。另外,我们还可以将借助一些ChatGPT的软件或浏览器插件,将这个保存成一个模板,以后我们需要时直接输入我们的画面即可,不需要重复输入基本提示。以iOS上一个叫“Chitchat”的软件为例:(chitchat的工作人员看到后,请给我广告费)
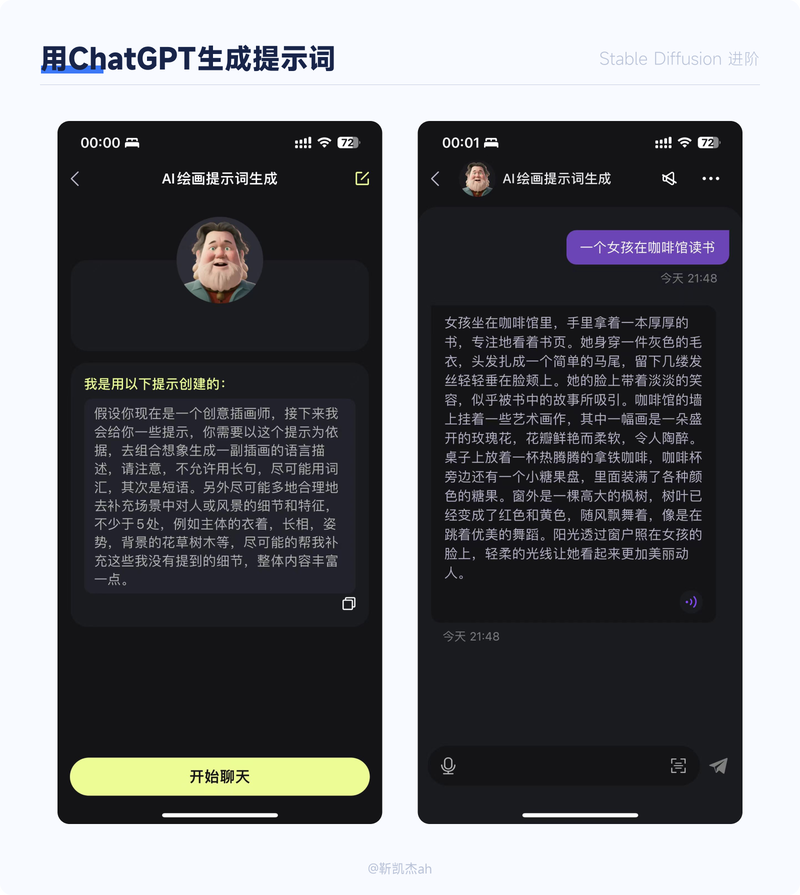
在这部分的最后,额外补充一个知识点:ChatGPT的提示语句式:“假设你你现在是XX专家,需要做XXX,请注意:要求1,要求2”,使用这样的句式会让ChatGPT的效果大幅提升。这个不是本文重点,这里不展开详述,感兴趣的小伙伴可以加我微信群详聊。
提示词管理
在开始之前,我想先说一下为什么推荐这样做。虽然网上有很多所谓的提示词大全,但我不建议直接替换自己的提示词管理,原因如下:1. 我们不需要那么多的风格,过多的提示词会增加使用成本和管理难度。2. 我们不知道未经使用的提示词具体会给图片带来什么变化。正是出于这样的考虑,我不想分享所谓的“海量优质提示词”,我认为这些东西的噱头价值大于实际意义,收藏后很可能就会被遗忘。授人以鱼不如授人以渔,我希望大家学会的是一种有效的提示词管理方法。这里推荐一个网站:https://moonvy.com/apps/ops/,我们可以在这里对我们的提示词进行管理。使用方法可以参考这个视频:https://www.bilibili.com/video/BV15N411P7D3/?vd_source=bd8f1862d445f4e01d7c1f49857dd474

现在的AI绘画技术主要采用了一种名为扩散模型的方法,这种方法能够使生成的图片呈现出独特且富有趣味性的效果。然而,这种方法也存在一个显著的问题,那就是生成的图片可控性非常差。在某些情况下,生成的图片可能会非常精美,而在其他时候,效果却可能不尽如人意。这使得设计师在使用此类工具时,很难确保能够满足客户的具体需求。然而,随着一种名为ControlNet的新技术的出现,这一局面得到了改善。ControlNet能够帮助设计师更好地控制AI绘画过程,从而使这个工具更加符合他们的实际工作需求。AI绘画不再仅仅是一个供人们娱乐的小玩具,而是逐渐发展成为一种能够真正帮助设计师提高工作效率的实用工具。虽然目前ControlNet的可控性仍然有待提高,但与之前的技术相比,它已经实现了质的飞跃。Controlnet插件的本质是利用图像作为输入信息的方式,以弥补语言在某些情况下的局限性。相对于语言而言,图像更加直观、简洁、易于理解,能够更加准确地传达信息。因此,Controlnet利用图像作为输入方式,可以更好地帮助AI理解我们的需求,从而生成我们所需要的图片。在图片中,包含了多种信息,例如线条轮廓、表面凹凸等。Controlnet插件的工作原理是使用特定的模型提取出特定的图像信息,然后将其输入给AI,引导AI生成图片。总的来说,我们可以将使用图片作为提示词视为补充语言的方式。这里补充一下,在文生图和图生图中用controlnet插件的区别,一句话说明白,需要生成新的图片用文生图,在原有图片上优化使用图生图。
插件安装与模型下载
插件安装
一般来说,网上的整合包已经包含了controlnet插件,不需要额外安装。安装方式:
1. 选择到从网址安装:https://github.com/Mikubill/sd-webui-controlnet(推荐)
2. 可以直接去这个链接这里下载https://github.com/Mikubill/sd-webui-controlnet/archive/refs/heads/main.zip,然后解压到extension文件夹
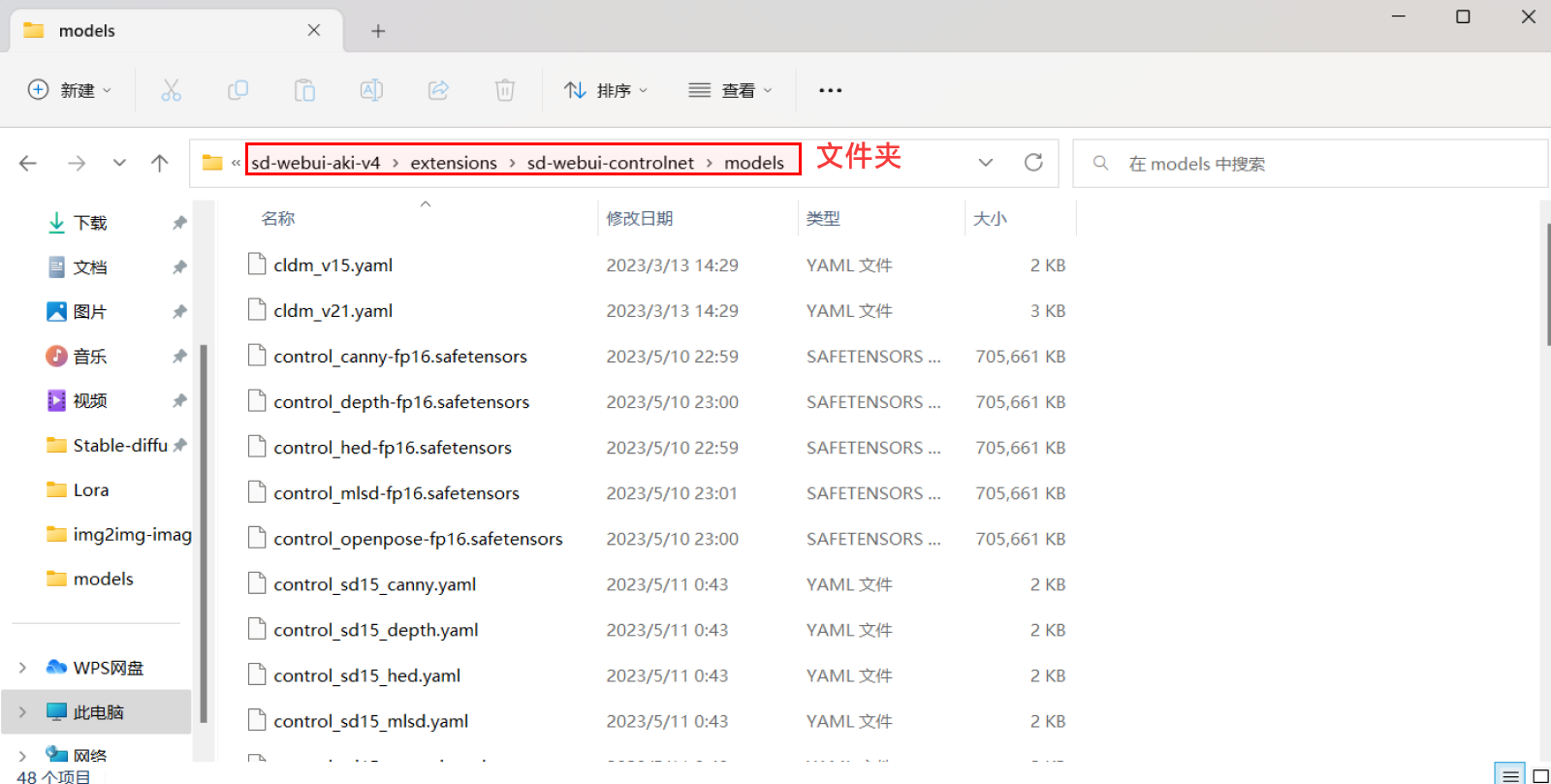
模型下载
我们可以直接去https://huggingface.co/lllyasviel/ControlNet-v1-1下载对应的模型,把这些后缀为safetensors的文件下载下来,然后放到这个文件夹中即可。
使用
基本使用流程
这里以最常用的canny模型为例,模式选择文生图,canny模型的作用就是提取出图片的线条信息并输入给AI。在界面最下面找到controlnet的插件,点击右边箭头展开参数,将这四个选项全部启用。
然后将预处理器和模型全部选择为canny,这里要注意,前面的预处理器与后面的模型要对应。接下来点一下这个爆炸的icon,在右边会显示所提取出的线条信息。
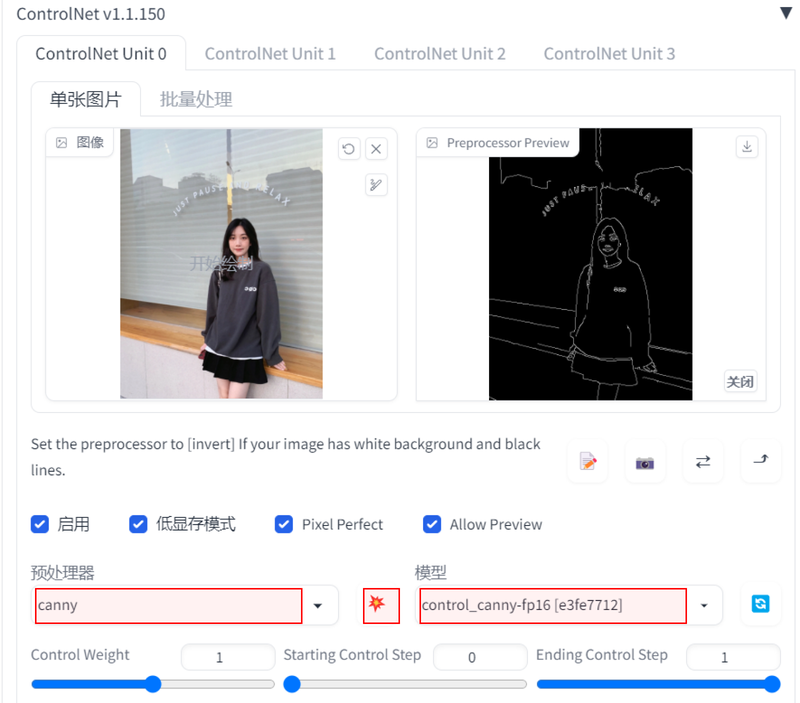
下面的那些参数我们先保持默认不变,接下来,修改采样器为DPM++2M Karras,总批次数修改为4,基础底模型改为“cetusMix_Coda2”,并且填入如下的提示词:正向提示词:masterpiece, best quality, ultra detailed, A girl, cute, light smile, black hair, purple eyes, yellow clothes, standing, outdoor, long sleeves,反向提示词:nsfw,(watermark),sketch, duplicate, ugly, huge eyes, text, logo, monochrome, worst face, (bad and mutated hands:1.3), (worst quality:2.0), (low quality:2.0), (blurry:2.0), horror, geometry, badpromptv2, (bad hands), (missing fingers), multiple limbs, bad anatomy, (interlocked fingers:1.2), Ugly Fingers, (extra digit and hands and fingers and legs and arms:1.4), crown braid, ((2girl)), (deformed fingers:1.2), (long fingers:1.2),(bad-artist-anime), bad-artist, bad hand然后我们点击生成即可。可以看到,最终生成的图片是在初始的真人的基础上生成的。

具体参数介绍
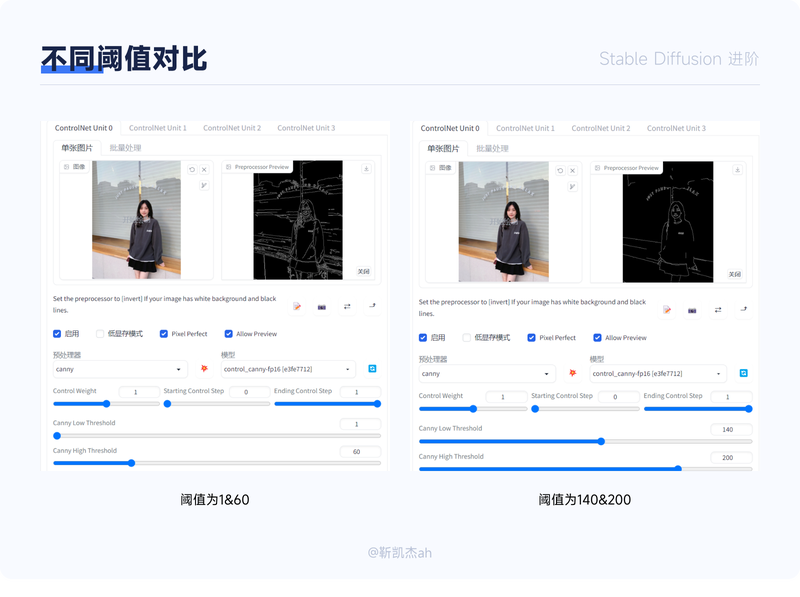
低显存模式:如果你的显卡内存小于等于4GB,建议勾选此选项。完美像素模式:勾选后,controlnet会自动去匹配适合的像素大小。允许预览:勾选后,点击爆炸icon,在图片右边会展示所提取的图片特征信息控制权重:可以调整该项 ControlNet 的在合成中的影响权重。引导介入步数&引导终止步数:controlnet对最终生成结果的控制步数范围比例。Guidance strength 用来控制图像生成的前百分之多少步由 Controlnet 主导生成。Guidance Start(T) 设置为 0 即代表开始时就介入,默认为 0,设置为 0.5 时即代表 ControlNet 从 50% 步数时开始介入计算。canny low threshold & canny high threshold更高的阈值下,所提取的线条更少,更低的阈值下提取的线条更多。
控制类型:更遵循提示词,更遵循controlnet输入的图像特征,或者均衡。
常用模型介绍
除了上面使用的canny,还有几个常用的模型,我在这里给大家介绍一下其他模型的用途。
Depth
通过提取原始图片中的深度信息,获得前后景的关系,可以生成具有同样深度结构的图。一般用于提取物体边缘轮廓,没有物体内部的细节。
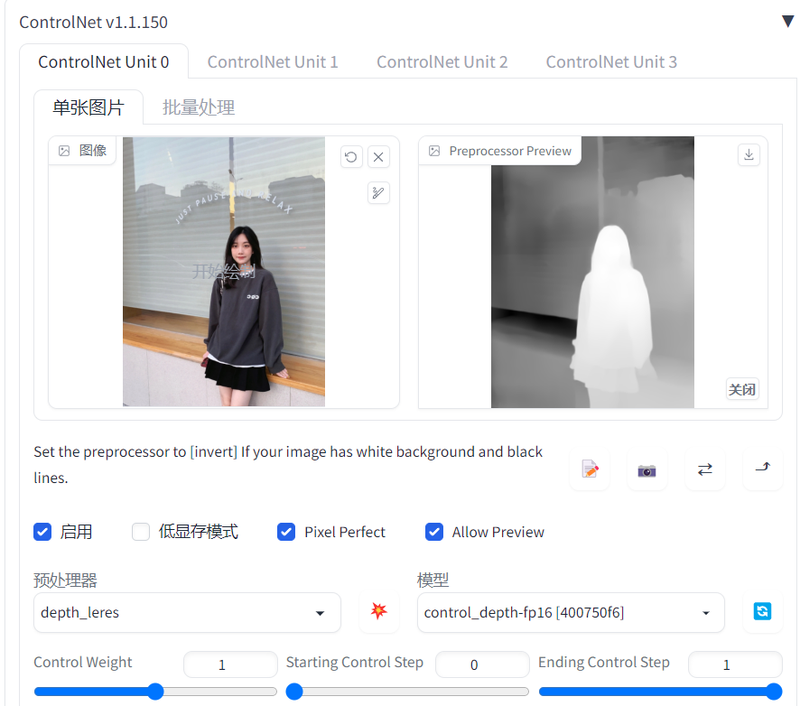
以这个模型为引导,生成的图片如下:

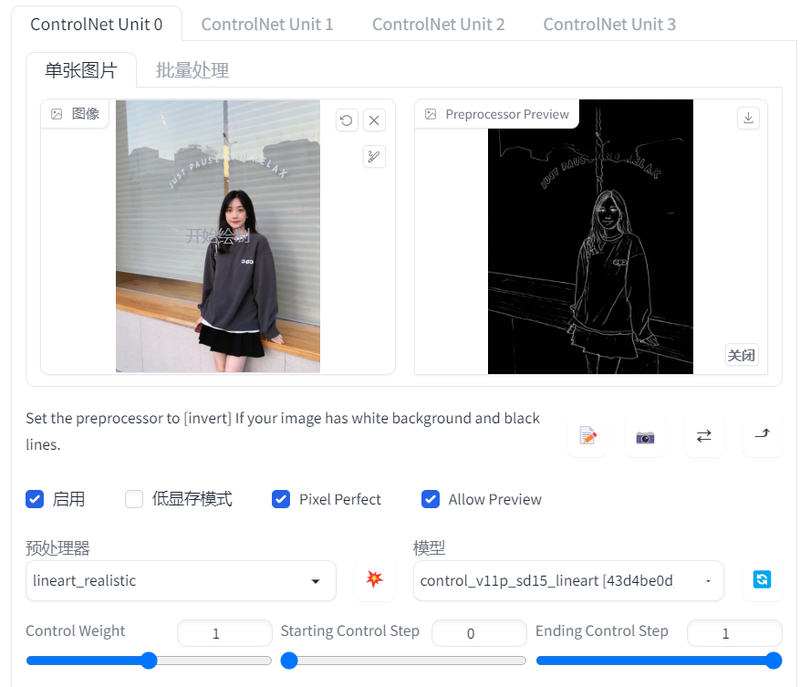
Lineart
与canny类似,该模型对线稿的处理能力极为优秀。同样也是将图形提取成线稿,然后在此基础上进行上色与细节补充。

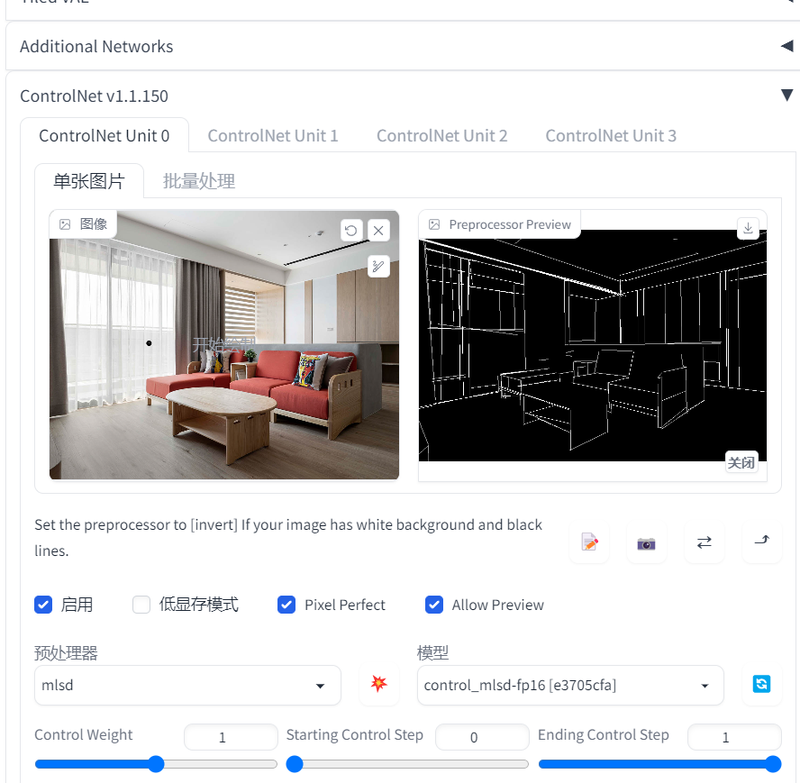
MLSD
该模型通过分析图片的线条结构和几何形状,来构建出建筑外框,适合建筑设计的使用。

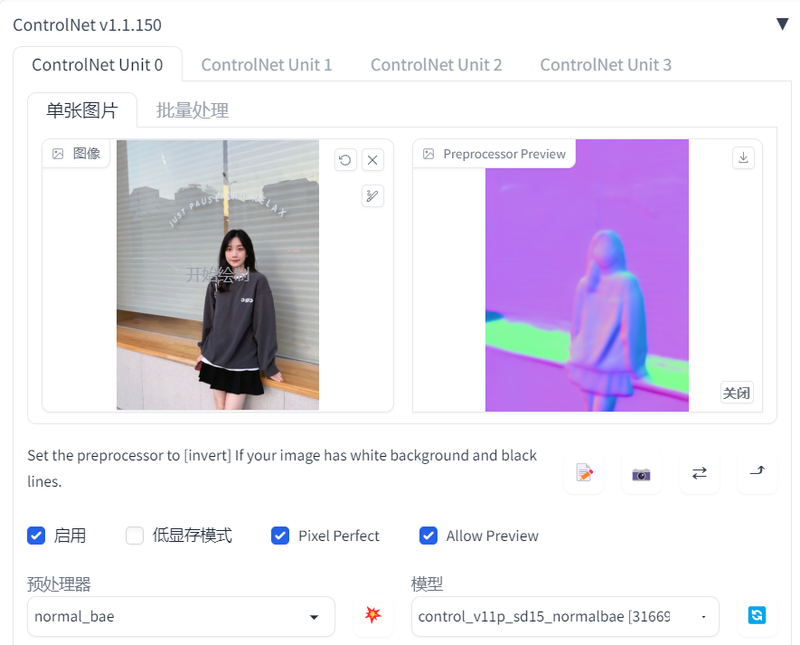
Normal
适用于三维立体图,通过提取图片中3D物体的法线向量,绘制出的新图与原图的光影关系完全一致。此方法适用于人物建模和建筑建模,但更适合人物建模。

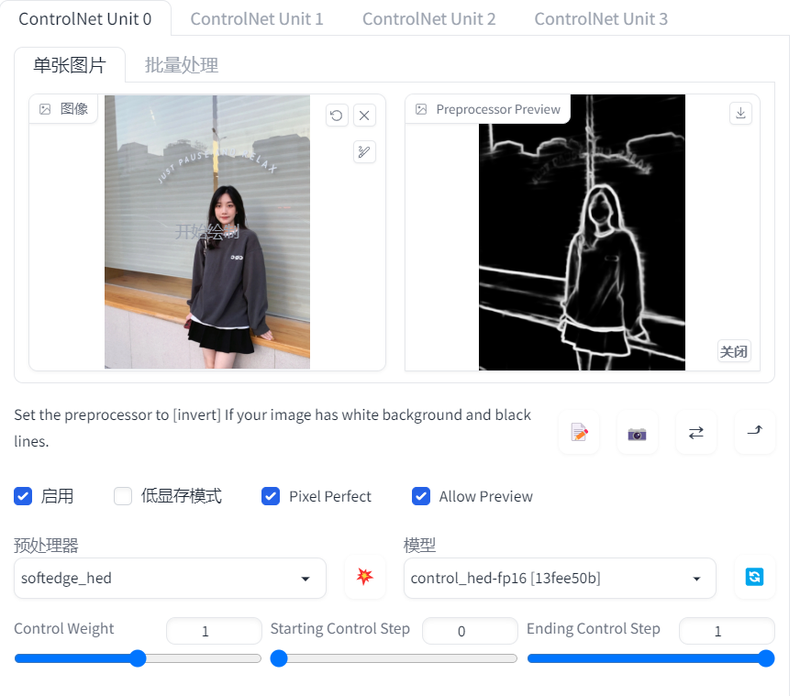
hed(边缘检测算法):
canny提取线稿更硬朗,hed提取的线条更圆润

OPENPOSE
根据图片生成动作骨骼中间图,然后生成图片,使用真人图片是最合适的,因为模型库使用的真人素材。
目前已经有五个预处理器,分别是openpose,openposefull,open posehand,openposefaceonly,openposeface,这五个预处理器分别可以识别身体姿态,姿态+手部+脸部,身体+手部,仅脸部,身体姿态+脸部。
我们这里以身体姿态为例,
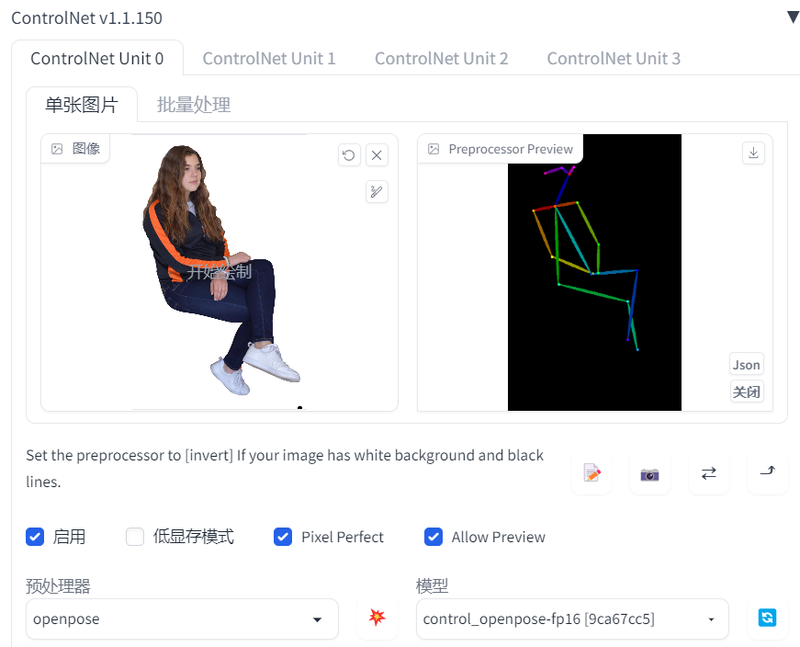
上图中右边便是openpose提取出来的人物骨骼图,以此引导生成的图像如下,可以看到,图像里人物的姿势都与原图保持了一致。

这里顺便给大家推荐一个网站:https://escalalatina.com/mujeres/sentada-azul-naranja/,可以从这里面下载人物的不同姿势的图片。
Segment
语义分割模型,标注画面中的不同区块颜色和结构(不同颜色代表不同类型对象),从而控制画面的构图和内容。
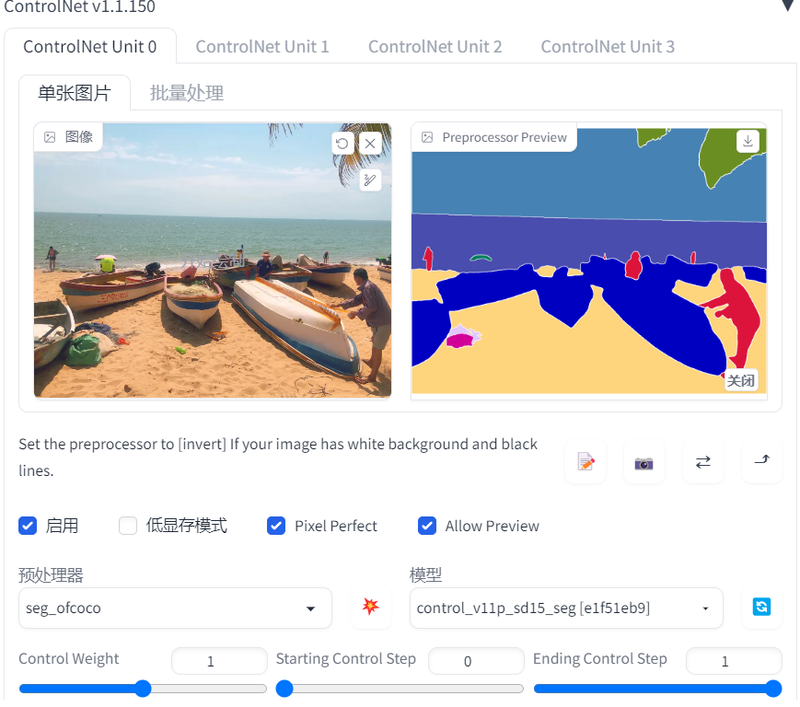
如上右图所示,每个色块代表不同的含义,完整的色块释义对照表如下:

原图文件链接如下:https://cowtransfer.com/s/3a5fc9e578ab44,各位自取即可。
在这个模型下,我们可以更自由地控制图片的生成。例如我们想要添加一个人,将预处理后的色块图下载后,在PS中添加一个人物轮廓的色块,颜色从表格中获得。然后再导入到controlnet中,注意这时预处理器要选择无,后面依旧选择seg,如图所示。
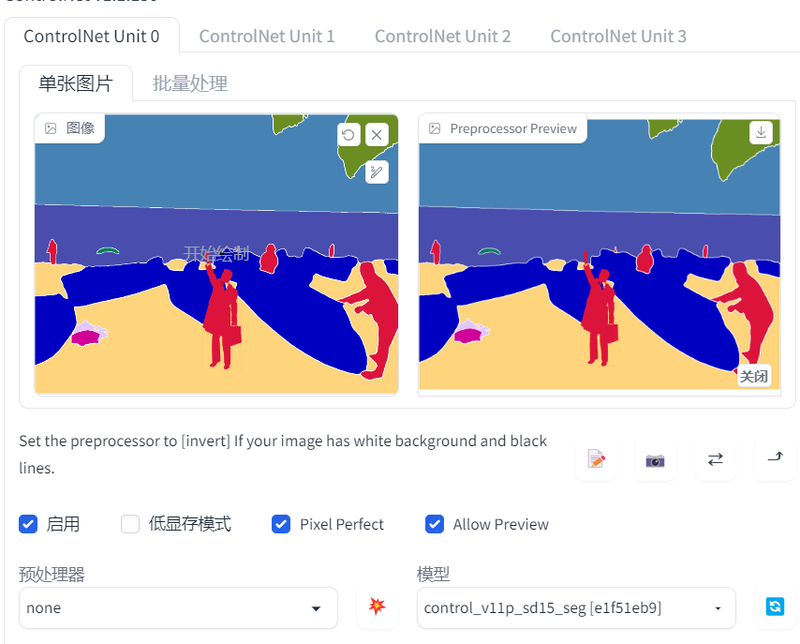
再次点击生成后,可以看到,图片按照我们的要求在中下部添加了一个拿箱子的人,并且由于我们选择的模型是二次元的,所以生成的图片也是二次元的。但整体的结构是遵循我们的指令的。


这里整理了一些大家在使用stable diffusion过程中遇到的常见问题,希望可以帮助到大家。
1. Vae模型是否必须要有?
不需要,现在的大模型很多已经自带了vae模型,我们即使不使用额外的vae模型也可以得到比较好的效果
2. 大模型和lora是否必须对应?
这个是不需要的,并且甚至我们可以对lora模型混搭使用。例如:
3. 我明明描述的是一个人,最终图像却生成了多个人?
一般来说多人的问题,大概率是图像尺寸过大,或者比例不对导致的。 为什么会出现这样的问题呢?这要从stable diffusion的底层训练集说起,stable diffusion V1.5的版本其实是基于512x512图像上进行微调的。当我设置的图片尺寸远大于512x512,或比例与1:1相差过大时,SD就会采用提示词中的部分进行填充,所以会出现多人或多头的情况。
解决方案:
a. 多抽卡。最直接的方案,生成很多张图,把多人或多头的图片扔掉,但是这种方案很浪费算力。
b. 尽量保持文生图时,直接生成的图像比例和尺寸在1:1和512x512左右,需要放大时采用文章中提到的措施进行。
4. 无法生成全身照,尽管我添加了“full body”这种词。
a. 使用512*768这样的纵向比例的图。
b. 在提升词中加入诸如“牛仔裤”此类的对下半身的描述词
另外,在遇到问题时,我们可以打开控制台,看一下控制台的报错,很多小的问题,我们都可以通过这里发现并解决。例如在我初次使用controlnet时,发现控制台报出来这样类似下载失败的错误,于是我手动下载控制台中的文件到指定的文件夹就解决了这个小问题。
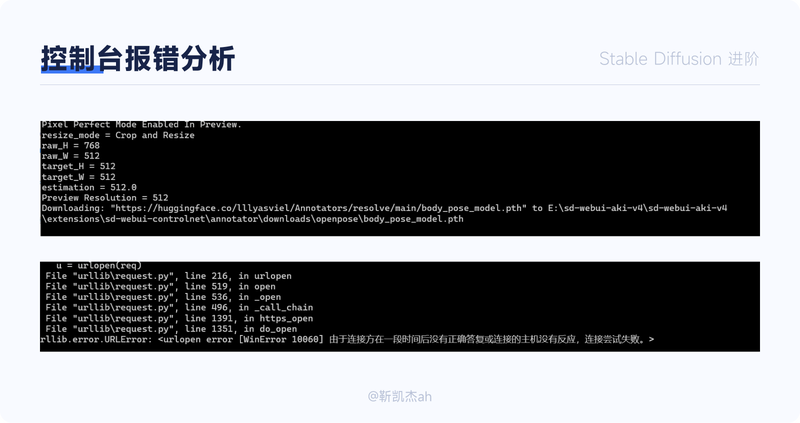
诸如此类的问题还有很多,善用控制台可以解决大部分的小问题。
后记如今,我们经常可以看到有关“学习AI,否则你就落后了”的文章和帖子,但是我认为这种说法并不完全正确。客观上说,chatgpt、mj等AI工具已经被非常广泛地运用,并且也确确实实地带来了生产力的提高,但是我们并不需要像设计师必须熟练掌握PS一样精通AI。相反,我们只需要保持好奇心,尝试一下,摸索一下,享受这个过程,无须把它当成考试或者培训。我们不应该被“不学AI,马上就会被替代”的焦虑所困扰。当前,AI绘画等技术也只是出现了不到1年的新事物,没有所谓的专家,只有在互联网上扮演专家的人,包括笔者在内,也只不过是AI绘画领域的小学生而已。科技日新月异,自去年AI绘画技术初现端倪以来,其成果已然大不相同,今日之AI绘画已愈发强大。因此,我们只需要保持兴趣即可,而非纠结于学习哪种技术、安装哪些插件。在这个新领域里,我们应怀抱好奇心,共同享受探索的乐趣,基于此,若能为生活、工作带来生产力的提升,那便是锦上添花。
愿诸君玩得开心。