算力说
2006年深度学习基本理论框架得到了验证,使得人工智能开启了新一轮的繁荣,2008年图像识别领域取得重大突破。然后自2011年深度学习在图像识别的准确率超过人类后,深度算法开始在各大领域展示强大的威力。各界对人工智能的讨论聚焦于深度学习及其相关的数据处理技术,但深度学习在可应用领域范围和技术成熟度方面是存在局限性的,这直接导致人类对该项技术的可靠性存在疑虑,需要科学家继续努力。
本期编译文章来自于Yann LeCun于2018年发表的关于“深度计算的潜能以及局限性”的演说。Yann LeCun将会讲述深度计算的三种主要实现方式,并且会着重阐释他们的局限性,大家将会了解到“卷积神经网络之父”的真知灼见。

Yann LeCun被誉为“卷积网络之父”,提出了神经网络的反向传播算法的原型,为Facebook首席AI科学家、纽约大学数据科学中心联合发起人。
【算力观点】
进入数字经济时代,在科学家和企业家的共同努力下,深度学习进一步推动人工智能在各个领域的落地,生产效率极大提升,随着以人工智能驱动的新生产方式的出现,产业链的价值分配可能会发生变化,或将出现以人工智能为特征的新经济周期。
早在上世纪80年代,基于深度学习的无人驾驶研究已经开展,尽管深度学习的潜力巨大,无人驾驶的研究也看似如火如荼,但一直没有实现商用,关键问题在于绝对安全性的证明,因此,解除人类对人工智能可靠性方面的疑虑将决定无人驾驶什么时候能够真正商用并且成为我们生活的一部分。
新一代人工智能: 挖掘机器的“感知”能力
人工智能技术的发展经历了几波浪潮, “上古时代”的人工神经网络以Marvin Minsky 和Seymour Papert在上世纪60年代撰写的《Perceptrons》为代表,这个阶段的人工智能更多的被称为“自适应滤波器”,很多技术理论成为人工智能技术之后进一步发展的基础和研究重点,比如机器学习和神经网络等深度学习基础理论。
当前人工智能最大的突破在于 “感知”能力,拥有“感知”能力的人工智能具备非常广阔的用途,比如无人驾驶和医疗影像,是目前呼声最高的实用场景,有望最快实现落地,其他场景包括智能翻译助手、内容搜索、游戏、安全和科学等领域。
AI感知能力升级:Mask R-CNN解锁动态影像识别技术
主流的深度学习离不开卷积神经网络和递归神经网络,神经网络由一系列的“块”组成,包含神经元和神经元网络层,各类输入值和权重等参数组成神经元(关于输入值和权重等参数,在上期Hintion大神的演讲中有详细阐述),通过不断调整参数在各层完成深度训练,最早期应用于支票和文件文档识别。
之后,人工神经网络的层数呈指数级的增长,为更高阶的应用提供了可能,比如点到点的无人驾驶,早在80年代一项名为“ALVINN”的无人驾驶研究,由卡耐基梅隆大学的Dean Pomerleau领衔的研究团队首次“解锁”,他们运用神经网络完成人类史上首次无人驾驶卡车试验,该应用研究后扩展至非道路环境。
自90年代开始,人工神经网络的深度训练开始使用更大的样本数据,但数据采集费时费力,直到互联网和数字世界的出现,数据采集效率才得以提升。
2008年成了图像识别技术的转折点, Facebook人工智能研究院(FAIR)在ICCV大会上发布了图像识别神经网络模型Mask R-CNN,它基于卷积神经网络,创新之处在于融入了实例分割算法(instance segmentation)完成图像精准甄别。
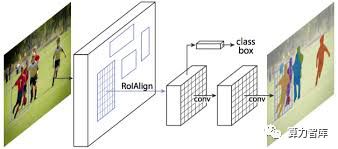
通俗的说,Mask R-CNN能识别出图像中的个体,而从前,人工智能只能识别大概的信息,比如只能识别“图像里面有一群人”,而不是“图像里面有几个人,他们分别在站哪个位置,他们摆了怎样的姿势”,正因为让图像识别的粒度变得更加细微,这篇论文获得了ICCV2017最佳论文(Marr prize),这个模型可应用在更复杂的场景,比如应用在增强现实和虚拟现实方面。
监督式学习的“十万个为什么”
计算机拥有了“感知”能力,但它还缺乏推理和预测能力。
早期,大多数科学家主要使用监督式学习训练机器的预测能力,而有几方面的问题一直都在被广泛讨论:
机器学习的傻瓜式学习法
机器在学习过程中不懂得取其精华去其糟粕,当信息源充斥着大量偏见必然影响机器学习的效果,而且这种效应有可能被放大,不过从技术上来说,剔除“偏见”是可行的。
人工智能的可靠性
人工智能被质疑的比较多的是可靠性,比如设计飞机的无人驾驶程序,并且先在测试系统中检验可靠性,但遗憾的是错误不可能避免,只是错误数量多少的问题。
机器学习的“自圆其说”
很多朋友都十分关心人工智能的工作原理,实际上工作原理的检查没什么难度,科学家有一百种方式去验证,人工智能并不总是需要“自圆其说”,只有在特定场景下才需要解释工作原理,比如在至关重要的决策层面,例如法律事务等方面。
深度学习三大技术路径:非监督式学习具有最广阔的前景
深度学习有三大主流技术路径,分别是监督式学习、强化式学习和非监督式学习,其主要区别在对于数据量的要求:
监督式学习(Supervised learning)
通俗的说,在监督式学习中,机器根据源源不断的输入值进行输出训练,来回比对“正确答案”,直到越来越靠近“正确答案”为止。
强化式学习(Reinforcement Learning)
对于强化式学习,机器是不知道“正确答案”的,而只知道评价结果的“好”或“坏”,若是“好”,机器会主动保留“好”的结果对应的参数,力求最大化“好”的概率,相比监督式学习,强化式学习的过程更自主,它要求更多的参数作为输入值,因此反馈的频次更少一些。
非监督式学习(Unsupervised learning)
非监督式学习又名预测式学习(Predictive learning),它的原理就像是让机器通过观察外部世界的运作方式完成学习,就像婴儿和动物的学习一样,下文将重点展开讨论。
按功能的强大性排序,预测式学习是最强大的,可完成更为复杂的学习。
生成对抗网络:更理想的深度学习模型,攻克不确定性难题
机器深度学习的终极目标是让机器做到通过观察就能完成学习,比如仅凭人的左边脸就可以“想象”出人的整张脸,意味着机器具备因果逻辑推理等能力,可基于已有信息预测未来(结果)。这个过程其实是 “常识”形成的过程,那它背后依托的是怎样的架构?
以预测式学习为例,完整的模型架构由3个核心要素组成:外部世界、代理层以及对象层。
外部世界:
外部世界提供所有形式的碎片化信息(文字、声音、图像等)。
代理层:
代理层接收外部世界的信息,通过“感知”对结果进行预测,然后根据对象层反馈的计算结果开展下一步工作,若结果是“满意”的,则皆大欢喜,代理层将沿着相同路径进行结果预判和未来规划,否则,代理层会继续要求得到的外部信息,如此往复循环,直到“满意”结果出现为止。
对象层:
对象层根据代理层的结果判断输出结果是否达到“令人满意”的水平,对象层好比人脑的 基底核(中枢神经元聚集的地方),负责“提醒”我们开心、疼痛、饥饿等切身感受。
但这样的模型也是存在短板的,即,它不能基于不确定性完成预测,比如机器只能预测铅笔立起来之后一定会倒下,但无法预判往什么方向倒下,对于人类也是一样的。
直到生成对抗网络(Generative Adversarial Nets,GAN)的出现,为不确定性难题的提供了解决思路,GAN有两个主要组成部分,生成器(Generator)和鉴别器(Discriminator),之所以称为对抗网络,通俗的说生成器负责“造假”,鉴别器负责“打假”,工作原理是:生成器根据随机信息产生任意输出值,输出值的用途是“迷惑”鉴别器,鉴别器辨别输出值的真伪,从而提升鉴别假信息的能力,反过来不断提升生成器的输出值的“仿真度”,终极目标是生成器自主完成可信度极高的预测,比如以下看到的是通过GAN生成的狗的图片,从左图到右图,就是通过GAN让AI绘制越来越逼真的狗的过程。

GAN在预测方面的强大已经被用于图片和视频制作,未来有望在更实用的场景发挥作用,比如用于交通工具的行进路径预测。
未来预测:人工智能成常规操作,怎样的价值才能永存?
人工智能和机器学习将会改变人们对于生产内容的价值判断。
纯手工的陶瓷器皿可高达750美元,因为它是百分之百纯手工的,陶瓷工艺已有8000年历史,物以稀为贵,所以将来机器制造的产品价值会越来越低,意味着强调融入感情色彩的创意类和艺术类的职业的前景会越来越光明。
人工智能是基于人类需求设计出来的自动化机器,它可以大幅度提升各行各业的生产力,但这需要约10-20年才能全面实现,就如同历史上发生过的工业革命一样,有一些问题是必然存在的,比如技术进步与失业率之间的矛盾,意味着机器很快会学会人的技能,并超越人类,这样反过来会制约技术的进步,所以经济学家们预计存在一个失业率的临界点,一旦超过了这个临界点,技术进步将会受到严重限制。
原视频链接: