
zstd
.zst.gz.xz.lz4
Development branch status:
Benchmarks
Linux ubu20 5.15.0-101-generic
Compressor name Ratio Compression Decompress. zstd 1.5.6 -1 2.887 510 MB/s 1580 MB/s zlib 1.2.11 -1 2.743 95 MB/s 400 MB/s brotli 1.0.9 -0 2.702 395 MB/s 430 MB/s zstd 1.5.6 --fast=1 2.437 545 MB/s 1890 MB/s zstd 1.5.6 --fast=3 2.239 650 MB/s 2000 MB/s quicklz 1.5.0 -1 2.238 525 MB/s 750 MB/s lzo1x 2.10 -1 2.106 650 MB/s 825 MB/s lz4 1.9.4 2.101 700 MB/s 4000 MB/s lzf 3.6 -1 2.077 420 MB/s 830 MB/s snappy 1.1.9 2.073 530 MB/s 1660 MB/s--fast=#
Zstd can also offer stronger compression ratios at the cost of compression speed. Speed vs Compression trade-off is configurable by small increments. Decompression speed is preserved and remains roughly the same at all settings, a property shared by most LZ compression algorithms, such as zlib or lzma.
Linux version 4.14.0-3-amd64
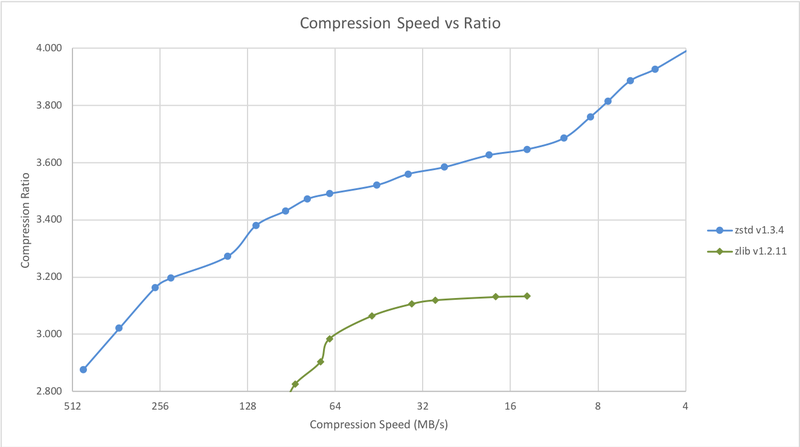
A few other algorithms can produce higher compression ratios at slower speeds, falling outside of the graph. For a larger picture including slow modes, click on this link.
The case for Small Data compression
Previous charts provide results applicable to typical file and stream scenarios (several MB). Small data comes with different perspectives.
The smaller the amount of data to compress, the more difficult it is to compress. This problem is common to all compression algorithms, and reason is, compression algorithms learn from past data how to compress future data. But at the beginning of a new data set, there is no "past" to build upon.
To solve this situation, Zstd offers a training mode, which can be used to tune the algorithm for a selected type of data. Training Zstandard is achieved by providing it with a few samples (one file per sample). The result of this training is stored in a file called "dictionary", which must be loaded before compression and decompression. Using this dictionary, the compression ratio achievable on small data improves dramatically.
github-users
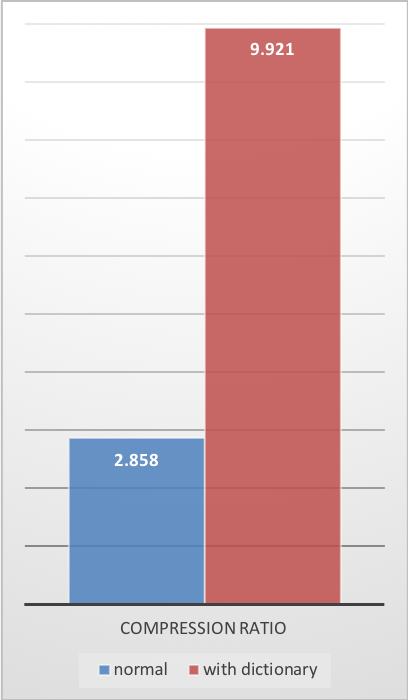
These compression gains are achieved while simultaneously providing faster compression and decompression speeds.
Training works if there is some correlation in a family of small data samples. The more data-specific a dictionary is, the more efficient it is (there is no universal dictionary). Hence, deploying one dictionary per type of data will provide the greatest benefits. Dictionary gains are mostly effective in the first few KB. Then, the compression algorithm will gradually use previously decoded content to better compress the rest of the file.
Dictionary compression How To:
zstd --train FullPathToTrainingSet/* -o dictionaryNamezstd -D dictionaryName FILEzstd -D dictionaryName --decompress FILE.zst
Build instructions
makemakezstdlibzstd
Makefile
makegmakemakezstdlibzstdlib/
Other available options include:
make installmake checkzstd
Makefile
lib/README.mdlibzstdprograms/README.mdzstd
cmake
cmakebuild/cmakezstdlibzstd
CMAKE_BUILD_TYPERelease
Support for Fat (Universal2) Output
zstd
cmake -B build-cmake-debug -S build/cmake -G Ninja -DCMAKE_OSX_ARCHITECTURES="x86_64;x86_64h;arm64" cd build-cmake-debug ninja sudo ninja install
Meson
build/meson
.travis.yml
Note that default build type is release.
VCPKG
You can build and install zstd vcpkg dependency manager:
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh
./vcpkg integrate install
./vcpkg install zstd
The zstd port in vcpkg is kept up to date by Microsoft team members and community contributors. If the version is out of date, please create an issue or pull request on the vcpkg repository.
Visual Studio (Windows)
build
build/VS_scriptszstdlibzstd
Buck
buck build programs:zstdbuck-out/gen/programs/
Bazel
You easily can integrate zstd into your Bazel project by using the module hosted on the Bazel Central Repository.
Testing
make checkmakeplayTest.shsrc/tests$ZSTD_BIN$DATAGEN_BINzstddatagenTESTING.md
Status
Zstandard is currently deployed within Facebook and many other large cloud infrastructures. It is run continuously to compress large amounts of data in multiple formats and use cases. Zstandard is considered safe for production environments.
License
Zstandard is dual-licensed under BSD OR GPLv2.
Contributing
devreleasedevrelease