价格屠夫又来了!开卷「本地私有化部署」服务价格,顺手上线和开源 DeepSeek-Coder-V2

6月17日晚,DeepSeek「深度求索」公众号发文,宣布上线和开源 DeepSeek-Coder-V2 大模型,包含 236B 和 16B 两种参数规模,API 支持 32K 上下文。
官方表示,这是「全球首个在代码/数学能力上与 GPT-4-Turbo 争锋的模型」,在代码、数学的多个榜单上位居全球第二,介于最强闭源模型 GPT-4o 和 GPT-4-Turbo 之间 👍👍👍

DeepSeek-Coder-V2 的价格依旧是非常低低低!而且官方宣布「本地私有化部署」服务售价仅仅 45 万/套/年,还包含了一台推理训练一体化的高性能服务器 (Nvidia H20、Huawei 910B 或其它同级别显卡,8 显卡互联) 👆 服务细则如上图左侧所示。
这意味着什么呢?意味着连友商报价的零头都没有… (上图右侧是智谱 ChatGLM 的本地私有化报价)。
“
如果你想体验 DeepSeek-Coder-V2 的代码能力,可以登录 **DeepSeek Chat 在线网站 (网站和 API 都是 236B 版本的模型)**,选择左侧「代码助手」。
我自己测了几个例子,的确体验非常丝滑,回答也很友好~
“
社群津津乐道的另一个话题,就是 DeepSeek 这个神秘团队,以及背后更神秘的 幻方。一家做量化金融的公司坚信 AGI,真的有点魔幻 😉
一年时间过去了,这个「旁门左道」的江湖怪侠,频频出招,搅弄风云,已经有成为一代大侠的气质 ⚔ 意料之外又觉得非常合理
蛮好的!中国有自己的「OpenAI」
上海交大「CS2916 大语言模型」课程完结!国内高校首门 LLM 技术前沿课,全明星讲师团队
上海交大春季学期开设的《大语言模型》课程 (代码 CS2916),上周刚刚完结🎊🎊🎊
这门课程定位与斯坦福大学 CS324「large language models」和 卡耐基梅隆 11-667「Large Language Models Methods and Applications」相似,聚焦于 LLM 领域的前沿技术发展,并且系统性地讲解 LLM 涉及到的基础知识体系。
“课程大纲
为什么是大语言模型 (LLMs)? 神经网络和深度学习基础 语言模型与表示学习 Transformers 和预训练语言模型 提示工程 (Prompting Engineering) 评估 (Evaluation) 大语言模型的并行训练 指令调整与对齐 (Instruction Tuning and Alignment) 奖励模型与强化学习人类偏好反馈 (RLHF) 代理 (Agent) 多模态 (Multimodal) 长上下文大语言模型 (Long-context LLM) 多模态大语言模型 (Multi-modal LLM)
非常值得一提的是,课程讲师团队非常豪华!
主讲老师 刘鹏飞 是上交清源研究院的副教授,同时也是生成式人工智能研究组负责人,非常之🐂🍺 而且,它还邀请了几位知名学者,讲授相关章节 (的确是国际一流AI课程的水准和风格):
- 邱锡鹏 (复旦大学教授,上海高校青年教师教学竞赛优等奖,著作《神经网络与深度学习》,MOSS大模型领导者)闫宏秀 (上海交通大学教授,主要研究方向:技术哲学、数据伦理、大模型安全对齐)魏忠钰 (复旦大学数据智能与社会计算实验室负责人,上海市青年教师教学比赛优秀奖,主要研究方向:多模态智能交互)颜航 (上海人工智能实验室青年研究员,主要研究方向:大语言模型)刘知远 (清华大学计算机系副教授, 清华大学教学成果一等奖,大模型技术相关领域取得多项创新成果)

课程官网有大纲 & 每章课件/阅读资料,感兴趣可以前往获取啦~
课程课件在努力保持专业度的基础上,加了中文解释,这点对中文学习者非常友好!!推荐的阅读资料非常精准完备,也赞一个 👍
不过,暂时没在公共平台找到课程视频,有点点遗憾 😭
“上海交大 · CS2916 大语言模型 课程官网→ https://gair-nlp.github.io/cs2916/docs/intro
斯坦福 CS324 → https://stanford-cs324.github.io/winter2023/
卡耐基梅隆 11-667 → https://cmu-llms.org
海辛Hyacinth 大佬录制的 ComfyUI 基础教程 (系列更新中),讲得非常好!
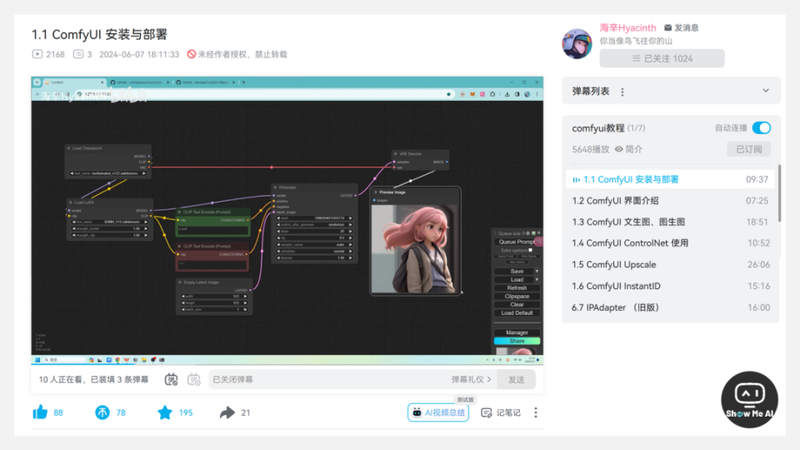
ComfyUI 专为 Stable Diffusion 设计,将图像生成过程分解为多个独立的节点。每个节点都有特定的功能,形成一个完整的工作流。用户可以灵活地调整和配置不同的功能节点,实现对模型的精准控制和高度定制化。
海辛Hyacinth 就不用多介绍啦~ 集美丽和才华于一身的AI视频创作者,影视创作和知识分享非常活跃 & 参与了龙年央视春晚的节目制作 🤙
海辛Hyacinth 最近正在 B 站陆续更新自己录制的 ComfyUI 基础课 📺 点击学习 截至6月16日,更新了7个视频,每个视频 10 分钟左右。
课程品质非常好,兼顾了基础和实战 👍 她从最基础的安装讲起,细节非常丰富,但实战感觉又很强,一点不拖沓,新手跟着学可以快速掌握最必要的操作技巧~
“课程大纲
ComfyUI 安装与部署:从 GitHub 页面开始讲起,详细演示如何下载、安装和配置ComfyUI
ComfyUI 界面介绍:各个界面元素的作用,以及最重要、最基本的操作 (节点、工作流等)
ComfyUI 文生图、图生图:文本生成图像、图像生成图像的详细步骤,演示整个操作流程 & 注意事项
ComfyUI ControlNet 使用:在 ComfyUI 中使用 ControlNet 来增强图像生成的完整操作流程
ComfyUI Upscale:在ComfyUI 中进行图像放大的4种主流方式,图像放大、潜空间放大、插件UltimateSDUpscale、开源Supir (目前效果最好)
ComfyUI InstantID:使用开源社区技术 Instant ID来进行角色换脸的完整操作,也就是仅输入一张参考图片,InstantID 就可以生成基于该角色的其他风格的图片
IPAdapter (旧版) :使用 IPAdapter 进行迁移学习的完整操作,也就是输入一张图像后,生成图像时可以学习到这张参考图像的风格特征
“B站课程网址 → https://www.bilibili.com/video/BV1rJ4m1M7jk
看视频时,偶尔能听到 海辛Hyacinth 打哈欠的声音?辛苦了!大家也记得关注和三连 ⭐
Devv 创始人分享,如何打造一个月入3万美元的AI搜索引擎
👉 这期日报 分享了YC 创始人 Paul Graham 的一篇经典长文「How to Get Startup Ideas」,日报详细整理了文章说到的十几种「创业 idea 来源方式」。
社区伙伴们反馈很活跃呀 😀 看来大家的确需要这种比较高屋建瓴的、系统的分享&指导。
想起来 Devv 创始人 @jiayuan 曾经分享过他这次创业的心得,与 Paul Graham 长文提到的创业技巧完美呼应!我们一起康康叭 👀
Devv.ai 是一款专为程序员设计的新一代 AI 搜索引擎,旨在替代开发者日常使用的 Google、StackOverflow 和文档查询场景,助开发者快速定位精确的代码片段和解决方案,提升编程效率。
“官网 (需要魔法) → https://devv.ai
jiayuan 在开篇就提到「Solving a Real Problem」,也就是从解决一个真正的问题开始。这跟 Paul Graham 分享的第一条完全一致。
为了确保观察到一个真正的问题,jiayuan 在项目开始之前跟 50 位不同背景的开发者进行了一对一的访谈,了解他们当前的痛点和解决方案,并最终达成共识:做一款专注于开发者的、可靠的搜索引擎。
他还在文中分享了几个关键节点,比如一周内 MVP 快速上线验证需求、确定差异化方向、大模型没备案导致中国市场被封禁(数据下跌严重)、出海、商业化…
而且,他还在社交平台 (推特 X 和即刻) 上非常活跃,积极分享产品使用技巧、技术路径、重大的产品更新!做得非常好 👍
产品构建经验
- 解决一个真正的、切身的问题。成功的创业公司往往能够解决用户的实际需求。通过MVP快速验证。避免一开始就追求完美,应该推出基础版产品进行快速验证。让你的产品与众不同。在市场竞争激烈时,通过独特功能和专注目标用户群体,使产品独具一格。口碑的力量。优秀的产品会自然引发用户间的推荐,尤其在开发者这样的紧密社群中更为显著。面对挑战是必经之路。创业之路充满挑战,关键在于保持适应性和持续进步。归根到底,Devv 的成功归功于对初步见解的坚持:开发者需要一个更优秀、更可靠的AI搜索工具,然后团队始终专注于解决这个核心问题并不断完善产品。
创业经验
- Y Combinator Startup School:免费的线上「创业速成班」,创业成功者和投资人们的讲座视频,涵盖了从创意到资金募集的各个方面。书籍《The Lean Startup (精益创业)》:Eric Ries 经典之作,强调快速实验与持续改进,是每位创业者的必读指南。Lenny's Newsletter:前 Airbnb 产品领袖 Lenny Rachitsky 的深度分享,涵盖产品管理和创业公司成长的深度内容。书籍《The Hard Thing About Hard Things (创业的艰难之路)》:Ben Horowitz 作为一名著名的风险投资人,在书中提供了经营一家创业公司可能遇到的挑战 & 坦率真诚的见解。创业必读。
创始人分享的原文 (英文) → https://www.indiehackers.com/post/how-we-built-an-ai-search-engine-for-devs-that-makes-30k-mo-SlB19aYcVZ8pGu3hNwhg
“Reddit 正文被 removed 但评论区挺精彩 → https://www.reddit.com/r/SideProject/comments/1bp4d43/how_we_built_an_ai_search_engine_for_devs_got
开发者推特 → https://twitter.com/forrestzh_?s=09
GenAI 设计模式全面指南:使用 LLM 时可参考的架构模式和心智模型

上面说到了如何获取创业/产品 idea,接下来就看看 GenAI 产品有哪些被验证的、可以依赖的设计模式,帮助你减轻和克服 GenAI 实现过程中的挑战,比如成本、延迟和幻觉等等。
当然,作者 Vincent Koc 也说到,这是他暂时经验的总结,而行业和技术的发展变动是迅速且剧烈的。
- 使用分层缓存策略驱动微调 (Layered Caching Strategy Leading To Fine-Tuning)多路复用AI智能体,用于专家模型组合 (Multiplexing AI Agents For A Panel Of Experts)微调LLM的多任务优化 (Fine-Tuning LLM’s For Multiple Tasks)基于规则和生成的混合规则 (Blending Rules Based & Generative)利用LLM的知识图谱 (Utilizing Knowledge Graphs with LLM's)GenAI之智能体的群体 (Swarm Of Generative AI Agents)模块化单体LLM方法与可组合性 (Modular Monolith LLM Approach With Composability)LLM的记忆认知方法 (Approach To Memory Cognition For LLM's)红蓝队双模型评估 (Red & Blue Team Dual-Model Evaluation)
作者不仅详细解释了每种模式的含义,还给出了架构图,以及可以参考的实现思路 & 可用的工具资源。
1. 使用分层缓存策略驱动微调
- 模式简介:采用分层缓存策略,通过存储对大型语言模型的初始查询结果,实现对后续相似查询的快速响应,有效降低成本和冗余,同时为模型的进一步微调提供数据支持,以提升专业任务的精确性和适应性。相关资源:GPTCache、缓存数据库如Redis、Apache Cassandra、Memcached。
2. 多路复用AI智能体,用于专家小组
- 模式简介:创建一个由多个专家级AI智能体组成的生态系统,每个智能体专注于特定任务,通过协作解决复杂查询,提供综合且多样化的解决方案,增强问题解决的深度和广度。相关资源:GPT-4、Phi-2、TinyLlama、通用模型或具有特定个性的 Llama。
3. 为多个任务进行LLM的微调
- 模式简介:通过对大型语言模型进行多任务微调,促进跨领域的知识和技能转移,增强模型在处理多样化任务时的多功能性和灵活性,适用于需要广泛技能的虚拟助手或研究工具。相关资源:DeepSpeed、Hugging Face的transformer库。
4. 基于混合规则和生成
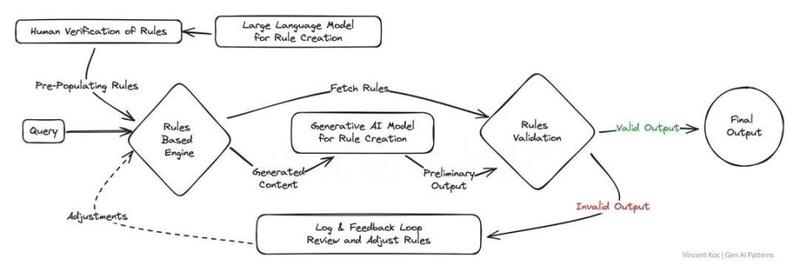
- 模式简介:结合生成式逻辑和基于规则的逻辑,创造出既符合严格规则又具有创新性的解决方案,尤其适用于那些需要在创新和合规之间找到平衡的行业。相关资源:电话IVR系统、传统聊天机器人。
5. 结合知识图谱使用LLM

- 模式简介:通过将知识图谱与大型语言模型相结合,赋予模型以事实为基础的强大能力,确保输出在具有上下文意识的同时,更加准确和真实,适用于对信息准确性要求极高的应用场景。相关资源:图形数据库服务如 ArangoDB、Amazon Neptune、Azure Cosmos DB、Neo4j;数据集和服务如 Google 企业知识图谱 API、PyKEEN、维基数据。
6. AI代理群
- 模式简介:借鉴自然界群体行为的智慧,通过大量AI智能体的协同工作,每个智能体提供独特的视角,共同创造出超越个体能力的集体智慧,特别适用于需要广泛创造性思维或处理复杂数据集的场景。相关资源:消息服务如 Apache Kafka。
7. 具有可组合性的模块化单体LLM方法(Moe)
- 模式简介:采用模块化的人工智能系统设计,允许系统根据任务需求动态调整配置,实现最佳性能,为企业提供高度定制化和适应性强的解决方案。相关资源:CrewAI、Langchain、Microsoft Autogen、SuperAGI。
8. LLM的记忆认知方法
- 模式简介:引入类似人类记忆的认知机制,使大型语言模型能够记住并利用先前的互动信息,提供更加个性化和细致的回应,尤其适用于需要持续对话或学习的环境。相关资源:向量数据库、NLP 库如 spaCy、BART 语言模型、开源解决方案 MemGPT。
9. 红蓝队双模型评估
- 模式简介:通过一个AI生成内容,另一个AI进行批判性评估的双模型设置,模拟严格的同行评审过程,为内容生成平台提供高质量的控制机制,确保输出的可信度和准确性。相关资源:微调模型、人工审查过程模拟工具。
“中文翻译版本 (翻得不错) → https://luxiangdong.com/2024/02/26/genaidm
哇!一份精彩的「深度学习 (DeepLearning) 历史回顾」:积硅步,至千里
康康我们又发现了什么好东西!
这是一份非常有意思的深度学习历史研究!
从前馈神经网络到 GPT-4o,深度学习逐步创建了一套日益智能的系统。作者对这段历史进行了研究,但并不是按照时间线,也没有讲技术细节,而是总结成一个思考框架:
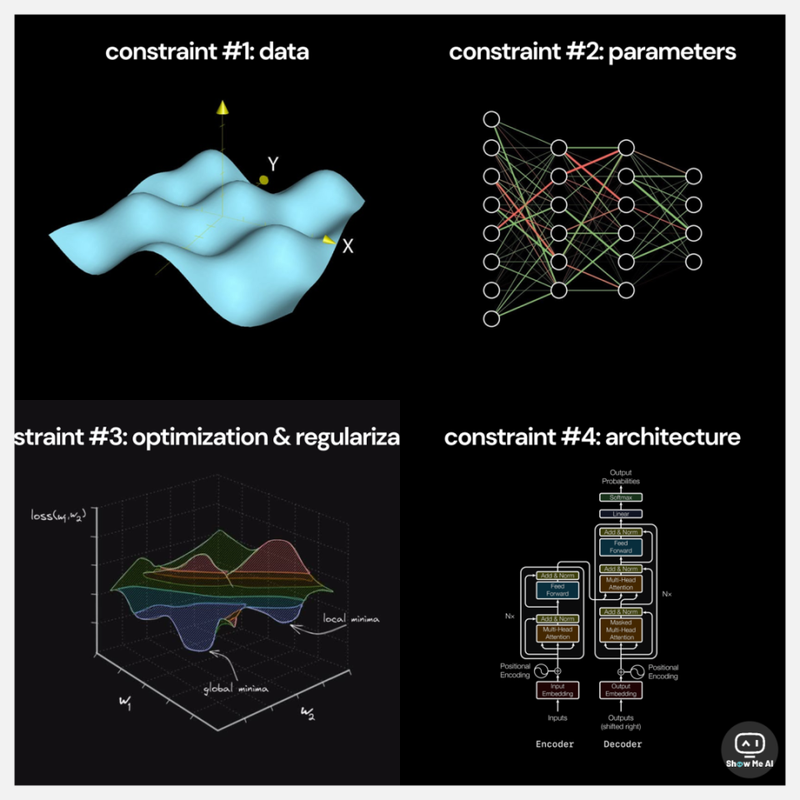
深度学习的约束条件,由数据、参数、优化与正则化、架构、计算、计算效率、能源 7 个部分组成。而深度学习领域的发展史,就是对这7个约束条件的突破史。
- 数据:模型的好坏取决于它训练的数据集。参数:模型的表征能力受其包含的参数数量限制。优化和正则化:模型在有效收敛的同时所能拥有的参数数量 (尤其是深度)受到优化和正则化方法的有效性的限制。架构:网络架构的质量限制了模型的表征能力。计算:总可用计算约束了模型可以具有的可训练参数的最大数量。计算效率:用于训练的软件实现限制了计算利用率的效率。能源:单个位置可从电网中提取的能量限制了可用于训练运行的计算量。
以下是更详细的内容大纲。