
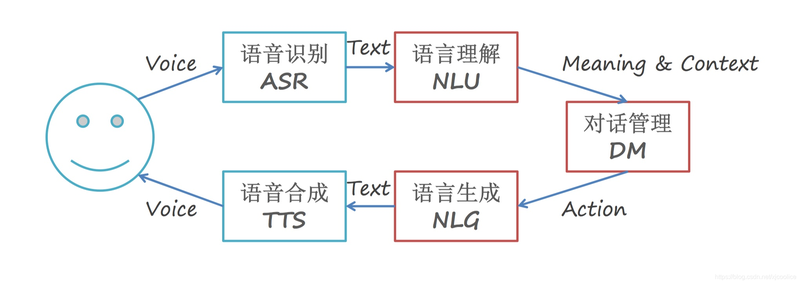
图1 是常见对话流的信息流动图。 首先,用户发出语音指令,1)通过语音识别ASR将语音转换为文本uu; 2) 文本通过语言理解NLU获得用户行为au; 3)通过用户行为生成对应系统行为au; 4)通过action生成对应的回复话术NLG; 5) NLG通过人工合成生成语音。
Dialog Management
对话管理(Dialog Management, DM)控制着人机对话的过程,DM 根据对话历史信息,决定此刻对用户的反应。最常见的应用还是任务驱动的多轮对话,用户带着明确的目的如订餐、订票等,用户需求比较复杂,有很多限制条件,可能需要分多轮进行陈述,一方面,用户在对话过程中可以不断修改或完善自己的需求,另一方面,当用户的陈述的需求不够具体或明确的时候,机器也可以通过询问、澄清或确认来帮助用户找到满意的结果。
对话管理包括如下任务:
- 对话状态维护(dialog state tracking, DST) 维护 & 更新对话状态 t+1 时刻的对话状态 st+1,依赖于之前时刻 t 的状态st,和之前时刻 t 的系统行为at,以及当前时刻 t+1 对应的用户行为at+1。可以写成 s t + 1 ← s t + a t + o t s_{t+1}\leftarrow s_{t} + a_{t} +o_{t} st+1←st+at+ot生成系统决策(dialog policy) 根据 DST 中的对话状态(DS),产生系统行为(dialog act),决定下一步做什么 dialog act 可以表示观测到的用户输入(用户输入 -> DA,就是 NLU 的过程),以及系统的反馈行为(DA -> 系统反馈,就是 NLG 的过程) DA 的具体介绍将在 NLU 系列中展开作为接口与后端/任务模型进行交互提供语义表达的期望值(expectations for interpretation) interpretation: 用户输入的 internal representation,包括 speech recognition 和 parsing/semantic representation 的结果


Initiative
对话引擎根据对话按对话由谁主导可以分为三种类型:
- 系统主导 系统询问用户信息,用户回答,最终达到目标用户主导 用户主动提出问题或者诉求,系统回答问题或者满足用户的诉求混合 用户和系统在不同时刻交替主导对话过程,最终达到目标 有两种类型,一是用户/系统转移任何时候都可以主导权,这种比较困难,二是根据 prompt type 来实现主导权的移交 Prompts 又分为 open prompt(如 ‘How may I help you‘ 这种,用户可以回复任何内容 )和 directive prompt(如 ‘Say yes to accept call, or no’ 这种,系统限制了用户的回复选择)。
Basic concepts
- Ground and Repair 对话是对话双方共同的行为,双方必须不断地建立共同基础(common ground, Stalnaker, 1978),也就是双方都认可的事物的集合。共同基础可以通过听话人依靠(ground)或者确认(acknowledge)说话人的话段来实现。确认行为(acknowledgement)由弱到强的 5 种方法(Clark and Schaefer 1989)有:持续关注(continued attention),相关邻接贡献(relevant next contribution),确认(acknowledgement),表明(demonstration),展示(display)。
听话人可能会提供正向反馈(如确认等行为),也可能提供负向反馈(如拒绝理解/要求重复/要求 rephrase等),甚至是要求反馈(request feedback)。如果听话人也可以对说话人的语段存在疑惑,会发出一个修复请求(request for repair),如
A: Why is that?
B: Huh?
A: Why is that?
还有的概念如 speech acts,discourse 这类,之前陆陆续续都介绍过一些了。 人的复杂性(complex)、随机性(random)和非理性化(illogical)的特点导致对话管理在应用场景下面临着各种各样的问题,包括但不仅限于:
Challenges
模型描述能力与模型复杂度的权衡
- 用户对话偏离业务设计的路径 如系统问用户导航目的地的时候,用户反问了一句某地天气情况多轮对话的容错性 如 3 轮对话的场景,用户已经完成 2 轮,第 3 轮由于ASR或者NLU错误,导致前功尽弃,这样用户体验就非常差多场景的切换和恢复 绝大多数业务并不是单一场景,场景的切换与恢复即能作为亮点,也能作为容错手段之一降低交互变更难度,适应业务迅速变化跨场景信息继承
Approaches
1) Structure-based Approaches
- Key Pharse Reactive Approaches 本质上就是关键词匹配,通常是通过捕捉用户最后一句话的关键词/关键短语来进行回应,比较知名的两个应用是 ELIZA 和 AIML。AIML (人工智能标记语言),XML 格式,支持 ELIZA 的规则,并且更加灵活,能支持一定的上下文实现简单的多轮对话(利用 that),支持变量,支持按 topic 组织规则等。
<category>
<pattern>DO YOU KNOW WHO * IS</pattern>
<template><srai>WHO IS <star/></srai></template>
</category>
<category>
<pattern>MOTHER</pattern>
<template> Tell me more about your family. </template>
</category>
<category>
<pattern>YES</pattern>
<that>DO YOU LIKE MOVIES</that>
<template>What is your favorite movie?</template>
</category>
- Trees and FSM-based Approaches Trees and FSM-based approach 通常把对话建模为通过树或者有限状态机(图结构)的路径。 相比于 simple reactive approach,这种方法融合了更多的上下文,能用一组有限的信息交换模板来完成对话的建模。这种方法适用于:
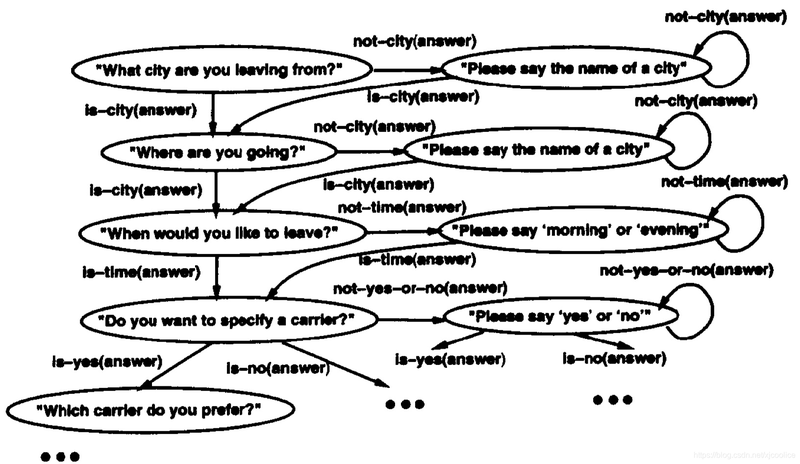
FSM 的状态对应系统问用户的问题,弧线对应将采取的行为,依赖于用户回答。
FSM-based DM 的特点是:
- 人为定义对话流程完全由系统主导,系统问,用户答答非所问的情况直接忽略建模简单,能清晰明了的把交互匹配到模型难以扩展,很容易变得复杂适用于简单任务,对简单信息获取很友好,难以处理复杂的问题缺少灵活性,表达能力有限,输入受限,对话结构/流转路径受限
对特定领域要设计 task-specific FSM,简单的任务 FSM 可以比较轻松的搞定,但稍复杂的问题就困难了,毕竟要考虑对话中的各种可能组合,编写和维护都要细节导向,非常耗时。一旦要扩展 FSM,哪怕只是去 handle 一个新的 observation,都要考虑很多问题。实际中,通常会加入其它机制(如变量等)来扩展 FSM 的表达能力。
2) Principle-based Approaches

Frame: 是槽位的集合,定义了需要由用户提供什么信息 对话状态:记录了哪些槽位已经被填充 行为选择:下一步该做什么,填充什么槽位,还是进行何种操作 行为选择可以按槽位填充/槽位加权填充,或者是利用本体选择 基于框架/模板的系统本质上是一个生成系统,不同类型的输入激发不同的生成规则,每个生成能够灵活的填入相应的模板。常常用于用户可能采取的行为相对有限、只希望用户在这些行为中进行少许转换的场合。
Frame-based DM 特点:
- 用户回答可以包含任何一个片段/全部的槽信息系统来决定下一个行为支持混合主导型系统相对灵活的输入,支持多种输入/多种顺序适用于相对复杂的信息获取难以应对更复杂的情境缺少层次 槽的更多信息可以参考填槽与多轮对话 | AI产品经理需要了解的AI技术概念
Agenda + Frame(CMU Communicator)
Agenda + Frame(CMU Communicator) 对 frame model 进行了改进,有了层次结构,能应对更复杂的信息获取,支持话题切换、回退、退出。主要要素如下:
- product 树的结构,能够反映为完成这个任务需要的所有信息的顺序 相比于普通的 Tree and FSM approach,这里产品树(product tree)的创新在于它是动态的,可以在 session 中对树进行一系列操作比如加一个子树或者挪动子树process agenda 相当于任务的计划(plan) 类似栈的结构(generalization of stack) 是话题的有序列表(ordered list of topics) 是 handler 的有序列表(list of handlers),handler 有优先级handler 产品树上的每个节点对应一个 handler,一个 handler 封装了一个 information item
从 product tree 从左到右、深度优先遍历生成 agenda 的顺序。当用户输入时,系统按照 agenda 中的顺序调用每个 handler,每个 handler 尝试解释并回应用户输入。handler 捕获到信息就把信息标记为 consumed,这保证了一个 information item 只能被一个 handler 消费。
input pass 完成后,如果用户输入不会直接导致特定的 handler 生成问题,那么系统将会进入 output pass,每个 handler 都有机会产生自己的 prompt(例如,departure date handler 可以要求用户出发日期)。


Information-State Approaches
Information State Theories 提出的背景是:

Plan-based Approaches
一般指大名鼎鼎的 BDI (Belief, Desire, Intention) 模型。起源于三篇经典论文:
- Cohen and Perrault 1979Perrault and Allen 1980Allen and Perrault 1980 基本假设是,一个试图发现信息的行为人,能够利用标准的 plan 找到让听话人告诉说话人该信息的 plan。这就是 Cohen and Perrault 1979 提到的 AI Plan model,Perrault and Allen 1980 和 Allen and Perrault 1980 将 BDI 应用于理解,特别是间接言语语效的理解,本质上是对 Searle 1975 的 speech acts 给出了可计算的形式体系。
官方描述(Allen and Perrault 1980):
A has a goal to acquire certain information. This causes him to create a plan that involves asking B a question. B will hopefully possess the sought information. A then executes the plan, and thereby asks B the question. B will now receive the question and attempt to infer A’s plan. In the plan there might be goals that A cannot achieve without assistance. B can accept some of these obstacles as his own goals and create a plan to achieve them. B will then execute his plan and thereby respond to A’s question.
重要的概念都提到了,goals, actions, plan construction, plan inference。理解上有点绕,简单来说就是 agent 会捕捉对 internal state (beliefs) 有益的信息,然后这个 state 与 agent 当前目标(goals/desires)相结合,再然后计划(plan/intention)就会被选择并执行。对于 communicative agents 而言,plan 的行为就是单个的 speech acts。speech acts 可以是复合(composite)或原子(atomic)的,从而允许 agent 按照计划步骤传达复杂或简单的 conceptual utterance。
这里简单提一下重要的概念。
- 信念(Belief) 基于谓词 KNOW,如果 A 相信 P 为真,那么用 B(A, P) 来表示期望(Desire) 基于谓词 WANT,如果 S 希望 P 为真(S 想要实现 P),那么用 WANT(S, P) 来表示,P 可以是一些行为的状态或者实现,W(S, ACT(H)) 表示 S 想让 H 来做 ACT
Belief 和 WANT 的逻辑都是基于公理。最简单的是基于 action schema。每个 action 都有下面的参数集:
- 前提(precondition) 为成功实施该行为必须为真的条件效果(effect) 成功实施该行为后变为真的条件体(body) 为实施该行为必须达到的部分有序的目标集(partially ordered goal states)
计划推理(Plan Recognition/Inference, PI): 根据 B 实施的行为,A 试图去推理 B 的计划的过程。
- PI.AE Action-Effect Rule(行为-效果规则)PI.PA Precondition-Action Rule(前提-行为规则)PI.BA Body-Action Rule(体-行为规则)PI.KB Know-Desire Rule(知道-期望规则)E1.1 Extended Inference Rule(扩展推理规则)
计划构建(Plan construction):
找到从当前状态(current state)达到目标状态(goal state)需要的行为序列(sequence of actions) Backward chaining,大抵是说,试图找到一个行为,如果这个行为实施了能够实现这个目标,且它的前提在初始状态已经得到满足,那么计划就完成了,但如果未得到满足,那么会把前提当做新的目标,试图满足前提,直到所有前提都得到满足。(find action with goal as effect then use preconditions of action as new goal, until no unsatisfied preconditions) backward chaining 在 NLP 笔记 - Meaning Representation Languages 中提到过。 还有个重要的概念是 speech acts,在 NLP 笔记 - Discourse Analysis 中提到过,之后会细讲。
更多见 Plan-based models of dialogue
值得一提的是,基于 logic 和基于 plan 的方法虽然有更强大更完备的功能,但实际场景中并不常用,大概是因为大部分的系统都是相对简单的单个领域,任务小且具体,并不需要复杂的推理。
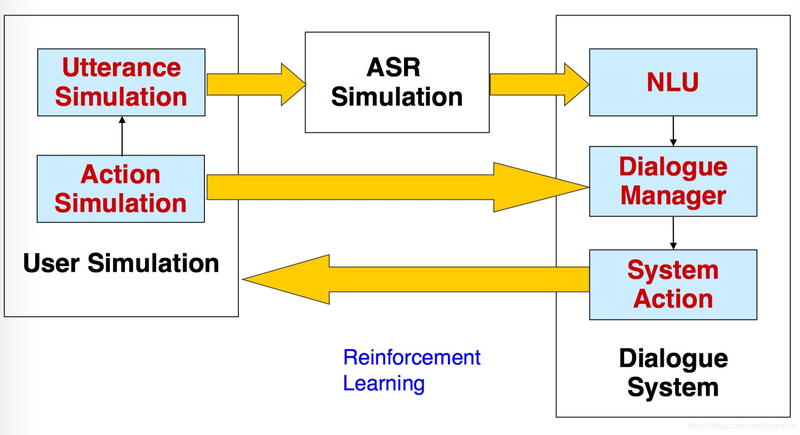
Statistical Approaches
参考文献
- [1] 知乎-多轮对话之对话管理(Dialog Management)[2]看人机对话技术一步步突破与发展